29th August 2017 #android #nexus7 Nexus 7 (2012)が自動バージョンアップによってアップデートされた最終バージョンがAndroid 5.1.1。このバージョンになってからひどく端末が遅くなり、使い勝手ががくんと落ちてしまいました。このため今では手元にある数少ないNFC対応端末として、Suicaの利用履歴をMoneyforwardのアプリケーションでMoneyforwardに転送するぐらいの使い道にしか使っていませんでした。
軽量で手頃なサイズなのでもう少し使い勝手が上がればいいなということと、単純に新しいAndroidを触ってみたいということでAndroid 7.1.2へバージョンアップしてみることにしました。いくつか失敗しながらとなったので備忘録として残しておきます。なおメーカーサポート外となりますので自己責任にて。
参考にしたサイト
手順
試行錯誤しながら+うろ覚え部分もありますがだいたい次のような流れです。
Nexus 7のデータをバックアップ
このアップデートのタイミングでデータは一度消去するのでバックアップをとっておきます
Nexus 7を開発者モードに
- 設定→端末詳細→ビルド番号でビルド番号を7回ぐらいタップ
- 設定→開発者向けオプションでUSBデバッグをONに
Android 7.1.2等をダウンロード
ROM 7.1.2_r33 NZH54D Grouper Tilapia F2FS/EXT4 Android 7.x AOSPに掲載されているものをダウンロード。
Gappsは最初Android 7.1 Nougat on Nexus 7 2012 WiFiに記載のあるOpenGappsを入れてみたのですがAndroid 7.1.2起動直後の初期設定アプリがクラッシュするためBeansGappsを使いました。
OpenGappsでもキャッシュをクリアしたりすれば大丈夫だったというような報告をみて試してみましたが、手元ではうまくいかず最終的にBeansGappsでは問題ありませんでした。
ブートローダーのアンロックとTWRPの導入
パソコンとNexus 7をUSB接続してブートローダーのアンロック。Platform Toolsのなかに入っているadbコマンドとfastbootコマンドを使います。
$ adb reboot bootloader
$ fastboot oem unlock
次にtwrpイメージの書き込み。twrpのファイル名は適当に読み替えてください。
$ fastboot flash recovery twrp-x.x.x-x-x.img
$ fastboot reboot
TWRP for Asus Nexus 7 2012 Wi-Fiに記載のあるとおり最後のリブートコマンド実行時にすこし注意が必要です。
Note many devices will replace your custom recovery automatically during first boot. To prevent this, use Google to find the proper key combo to enter recovery. After typing fastboot reboot, hold the key combo and boot to TWRP. Once TWRP is booted, TWRP will patch the stock ROM to prevent the stock ROM from replacing TWRP. If you don’t follow this step, you will have to repeat the install.
最後にリブートする際、Nexus 7のボリュームダウンボタンと電源ボタンを長押しします。これにより書き込んだカスタムリカバリーが自動的に工場出荷状態に戻されることを防ぎます。
OSとGappsの導入
あとはAndroid 7.1 Nougat on Nexus 7 2012 WiFiにある手順5から順に実行していきます。スクリーンショットをとらなかったのでスクリーンショットを参照されたい方は該当記事をご参照ください。
リカバリモードで起動。
起動するとコマンドが表示されているのですが、ボリュームアップ・ダウンで選択し電源ボタンで実行できます。ボリュームダウンボタンを何回か押して「Recovery Mode」を選んで電源ボタンで実行します。
この後の手順は下記の通りです。
- Wipeを選んでFactory Resetを実行します。
- TWRPのメインメニューまで戻り、Advanced→ADB Sideloadまで進みスワイプしてsideloadを開始します
- パソコンから
$ adb sideload aosp_grouper-7.1.2-ota-eng-20170811.ds.zipとコマンドを実行してOSイメージを書き込みます。 - 次にGappsを書き込みますが、またTWRPのメインメニューまでもどりAdvanced→ADB Sideloadまで進み、今度はWipe Dalvik Cacheを選択した状態でスワイプします
- パソコンから
$ adb sideload BeansGapps-Mini-7.1.x-20170725.zipとしてGappsを導入します。 - Reboot Systemを選択してリブートします。TWRPのアプリを入れるかどうか聞いてきますが、これはどちらでもよいでしょう。
その後の設定など
起動後にはAndroidの初期設定を進めていきます。Wifiの設定などを行い、設定を進めていけば完了です。Play Storeアプリはインターネット接続されていれば自動的にダウンロードされてきます。
13th April 2017 #azure #cloud #ipad #visualstudio 手元で使っている仕事用のIT環境というと、数年前からMacBook ProにせいぜいVirtualBoxやDockerを使った仮想環境というぐらいでした。ただ、いくつか不便なところも出てきたり、Windowsデスクトップ環境でのテストが必要になったりと要件が増えてきたのでいまはVisual Studio Cloudを使っています。加えて仕事上外出も増えたのでiPad Proを使うことも増えてきました。そのいきさつ等を記録がてら公開しておきます。
増えてきた要件と変わってきた要件
Windowsデスクトップ環境
手元に持っているハードウエアは仕事用も個人用も見事にほぼApple一色でiPhone、iPad Pro、MacBook Proといった組み合わせです。
OSの種類でいえば、macOSとiOSだけですが仕事がら、Windowsデスクトップ環境での検証がなんだかんだ必要になります。会社のPCにはWindowsのライセンスと仮想環境があるのでこれを使えば実用上困らないのですが、まっさらなWindows環境を準備したり、様々なバージョンのWindowsを準備するのはディスクが足りなくなったりかなりの手間もかかります。
手元にWindows 7、Windows 8.1などのライセンスも持っているのですが、Windows Server 2012R2が検証に必要になったり、最近ではWindows 10を検証したい場合も増えてきました。
iPad Pro
デモや検証のために会社のMacBook Proを出先に持ち歩いてもいいのですが、VMwareのような重量級アプリケーションを利用するとあっという間にバッテリーもなくなってしまいます。それに、MacBook Proも15インチ版を利用していると少々かさばるので持ち歩きには不便なときもあります。
このため最近では出先にiPad Pro (SIMフリーモデル)だけを持っていていくことも増えてきました。作成した書類はすべてDropboxに入れてありますし、別途個人的にOffice 365 Businessも契約しているのでExcelやPowerPointなどが必要になってもiPadからでも利用できます。iPadからHDMIやVGAへの変換端子を使えばプレゼンテーションもiPadから可能ですし、Apple TVが会議室に設置されていればそのまま投影することもでき、パソコンを使うよりも便利な場合さえあります。
iPad Proを使っていて最も便利と感じるのはインターネット接続です。Wifiモデルではなく、SIMフリーモデルを利用してIIJmioのデータ用SIMを入れているので、テザリングやWifiルータなどは別途必要ありません。一昔と比べればiPhoneからのテザリングやWifiルータの操作も幾分か簡単になったのですが、それでもネットワーク接続のためにあれこれ操作するのは一定の煩わしさがあります。
出先でiPadのような端末を使いたいというときの利用シーンは議事メモ、スケジュール確認、仕様などの確認、プレゼンテーション、デモといったところでしょうか。このような使い方であれば、iPadは今のところおおよそ丸一日持ち歩いてもバッテリーは十分持ちます。
クラウドの選択肢
クラウドもこれまでAmazon Web Services、OpenStack、OpenShift、DigitalOcean、Herokuなど様々利用してきました。その中でもいまVisual Studio CloudとAzureを使っているのはほぼ消去法での選択です。理由はWindowsデスクトップ環境が使えて簡単にいろんなWindowsバージョンを試せるところです。
(なお、Azure上でWindowsデスクトップ環境を使うにはVisual Studio Cloudの年間サブスクリプションが必要です。詳しくはVisual Studioのサイトにてご確認ください)
Windowsデスクトップ環境を使うには有名どころとしてAWSのWorkSpacesを使う方法もあります。WorkSpacesも一月ほど試しに使ってみてかなり便利であることは実感しました。ただ頻繁に検証用に環境を作り直したかったので目的には合いませんでした。
AzureでのWindowsデスクトップ環境
よく使うところとしてWindows 7 Enterprise N、Windows 8.1 Enterprise N、Windows 10 Enterprise N、Windows Server 2012 R2 Datacenterなどのバージョンを使っています。仮想環境を新規作成するとしてもだいたい5分くらい待てばできあがります。デスクトップ環境にはRemote Desktopアプリケーションを利用しますがこれは、Mac版もiPad版もあります。Amazon WorkSpacesと比べればUIなどすこし使いづらいですが、慣れとして割り切って進めましょう。
特に混乱するのはiOS版Remote DesktopではCmdキーはWindowsのCtrlキーにマップされているものの、Mac版Remote DesktopではマッピングがないためmacのアプリからコピーしRemote DesktopでペーストするにはCmd+C → Ctrl+V といった操作になり頻繁に操作ミスします。このマッピングを設定的に変更する方法はすこし調べた限りは無いようで、慣れるしかありません。
仮想環境のお値段
Visual Studio Cloudの年間サブスクリプションを購入すると毎月50ドル (5,500円分)のクレジットが付与されます。初期設定ではもし利用がこの枠を超えてしまった場合には仮想環境がすべて停止するだけで追加で請求されることはないようですから安心です。クラウドの価格は頻繁に変わりますので随時ご確認いただくとして、ここでは手元の実績をすこし紹介しておきます。
まずVisual Studio Cloudで仮想環境を立ち上げる際、利用できるリージョンには制限があります。残念ながら執筆時点で利用できるリージョンに日本は含まれていません。韓国などアジア地域のリージョンで利用可能なところはありますが、日本が使えないなら一番安いリージョンにしようということで今はもっぱらWest US 2を利用しています。
仮想マシンはSSDタイプのDS1_V2 (1コア、3.5GBメモリ)を一番よく使っています。執筆時点での見積もり利用料金は4,401円/月です。これは稼働させっぱなしの場合での見積もりです。停止している間もストレージなどの利用料金は発生し、SSDの仮想マシン1台ぶんで1,500円/月ぐらいです。これまで実績利用時間としては週数時間ずつぐらいですが、おおよそ2,000円前後といったところでした。
データ転送などでも料金がかかりますが通常の利用方法であれば、5,500円のクレジットでおおよそ仮想マシン2台分ぐらいは常に作成済みの状態で使える換算になります。
West US 2での使い勝手
大陸をまたぐのでレイテンシの点について気にしていましたが、たまにもたつく印象のときもありますが慣れでカバーできる範疇と思えるようになってきました。YouTubeなどを再生しても十分再生が追いつきますし、ネットワーク環境の充実と技術の進歩には驚かされます。
Visual Studio Team
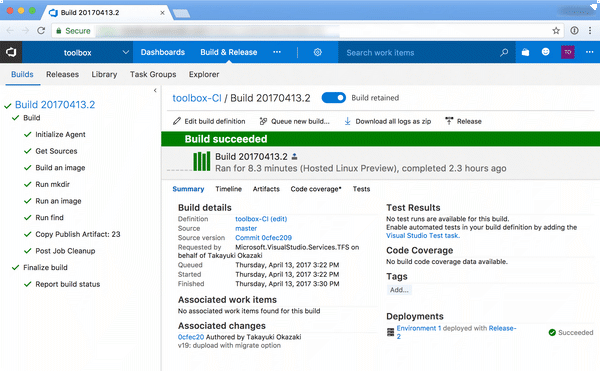
ほとんどWindows仮想デスクトップのために利用しているVisual Studio Cloudですが、せっかくなので他の付属サービスも使い始めています。いくつか最近Goでツールを作っているのですが、固定したCI環境を準備していなかったので今回はVisual Studio Teamに作ることにしました。
git pushをトリガーとしてビルドもできますし、成果物をビルドごとにパッケージにすることもできます。どちらかというと、Webアプリケーション向けにデプロイするという流れのUIになっていますが、ビルドにDockerも使える点が便利です。
いまDockerイメージをDocker HUBからダウンロードしてくるだけで5〜6分かかってしまうところが難点ですが、もう少し本格的に困ったら解決方法を探すことにします。
まとめ
Visual Studio CloudとAzureを使ってアプリケーション開発環境もそうですし、検証やデモといった作業もほとんどクラウド上で行える環境ができあがってきました。時々まだパソコンでなければできない操作もありますが、ほとんどの作業はiPadからも作業できるようになってきました。
パソコンはたくさんのメニューやショートカットを使いこなしててきぱき作業するのに向いていますし、iPadのようなデバイスは出先で主要な用事を片付けるためにかなり役立ちます。
使い分けはまだまだ必要でしょうけれど一つ変わったのはパソコンのスペックについての考え方です。Azure上のWindows仮想デスクトップは必要に応じて簡単にメモリーやCPUコア数などを追加できます。手元のMacBook ProにはCore i7 6920という比較的高スペックなものが乗っていますが、一方のAzureではサーバ用のXeon E5-2673といったCPUを使っているようで、クラウド上で処理した方が早い場合もあります。
手元のデバイスはいかに手になじんで、目に優しいかが大事でスペックについてはそろそろ妥協していい時代になってきているのかもしれません。
6th April 2017 #docker #glide #go #go-sqlite3 #sqlite3 Part of my Go app in my project, toolbox, using go-sqlite3. I spent couple of hours to setup cross compiling environment for this.
go-sqlite3 using CGO for binding sqlite3 to go library. That requires cross compilers for each target platform. First, I tried to setup mingw64, etc for each platform. But it was easy to implement if you are familiar with xgo.
xgo is a Docker images that pre configured for each Go version and target platforms. If you are using glide for packaging system. Prepare Dockerfile like below.
FROM karalabe/xgo-1.7.x
RUN apt-get update -y
RUN apt-get upgrade -y
RUN apt-get install -y zip git curl
ENV GOBIN=/usr/local/go/bin
ENV PATH=$PATH:/usr/local/go/bin
RUN curl https://glide.sh/get | sh
Then, just build with xgo command like below.
xgo --ldflags="$LD_FLAGS" -targets "windows/*,linux/*,darwin/*" github.com/watermint/toolbox/tools/$t
31st March 2017 #asana #mathematica 大学で使ってからもう十数年ぶりになりますがMathematicaをさわっています。数学とあとは機械学習関連を勉強するためMathematicaのHome版を購入してみました。まずはデータを分析したりするところから手始めにやってみようと思っていますが、 十数年ぶりということもありますし、大学時代もさほど深く使い込んでいなかったのでWolfram Languageの知識はほぼゼロの状態です。
慣れたプログラミング言語で書けばすぐできることですが、手始めにAsanaで管理しているタスクを集計したり分析する流れをやってみました。AsanaのタスクはJSON形式でエクスポートができますのでこれを読み込んで集計してみます。
JSONを読み込むにはImportを使いますがこのとき、”JSON”ではなく、”RawJSON”をつかうとすべてがAssociation(連想配列のようなもの)として読み込むことができます。ここまでくるだけで結構つまづきました。Asanaから得られるJSONは”data”というキーが最初にあるのでいろいろなプログラミング言語の連想配列と同じように["data"]のように書いて値を取得します。値が取り出せたので続いて集計です。
AsanaのJSON書式はAPI referenceあたりを参照しながら処理を進めましょう。たとえばタスクが作成された日時は、”created_at”というキーに対する値として設定されています。時刻の書式はISO 8601形式です。
ISO8601形式をMathematicaで読み込むには DateObject["2017-03-31T09:00:00Z"]のようにDateObjectへ渡してやればよいようです。
手元のAsanaデータは1月中旬に整理整頓してそれ以前はあまり正確ではありませんでしたから、1月中旬以降のものだけを集計対象としています。
asanaTasks =
Select[asanaJSON,
DateObject[#["created_at"]] > DateObject[{2017, 1, 15}] &];
集計対象としたいタスクだけを取り出すにはSelect関数を使えば良いようです。関数型言語でプログラミングした経験があれば比較的すんなり理解しやすいかと思いますが、&のような簡略書式はMathematica独特なのでこれはマニュアルや例をみながら見様見まねで覚えるしかなさそうですね。
集計をするときもCountsByのような関数で簡単に集計できます。関数がたくさんあるので、プロトタイピングするにはもってこいです。
週ごとに集計するために日付を丸めたかったのですがこれがなかなかわからず苦労しました。
taskCountPerWeek = CountsBy[
asanaTasks,
CurrentDate[
DateObject[#["created_at"]],
"Week"
] &
];
最近出た11.1というリリースで追加されたCurrentDateを使うと簡単にできるようです。CurrentDate[Now, "Week"]のように日付の粒度を指定すればその粒度で値がかえってきます。語感としてややこしいのは、CurrentDateとありますがDateObjectなどを渡してやれば与えた日時を基準に変換してくれます。
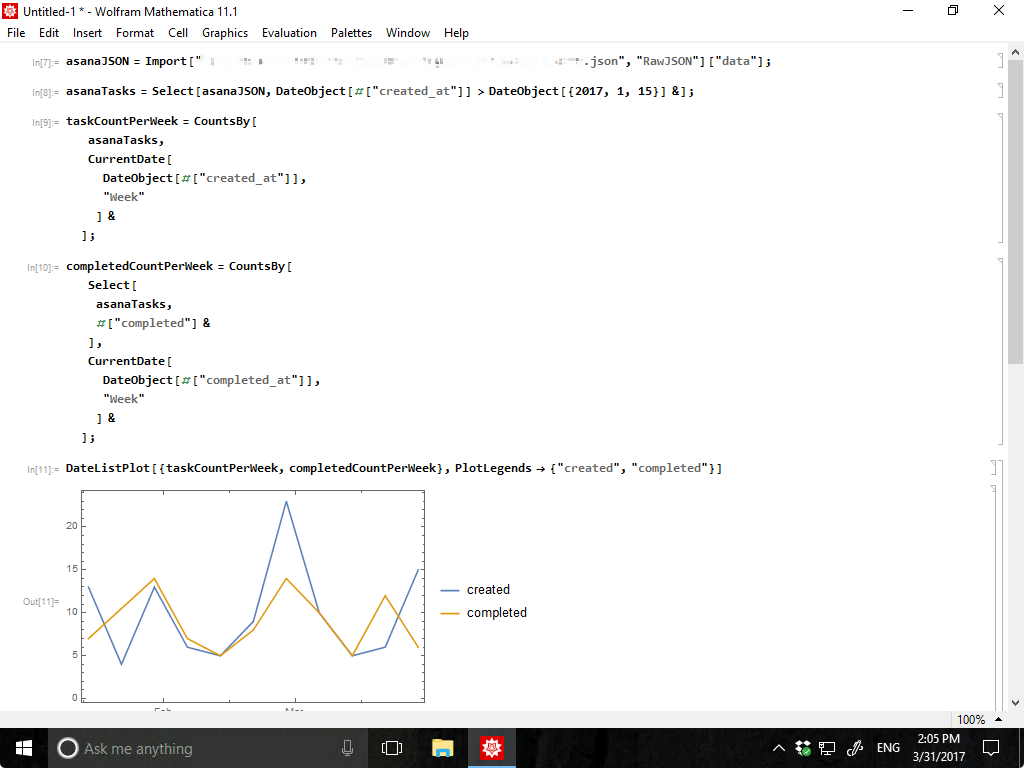
最後にDateListPlotでグラフを書けば週ごとにどれぐらいタスクが作成されているかわかりました。
21st February 2017 #api #dropbox #dropboxbusiness #python I wrote sample script of Properties API of Dropbox Business in Python.
Note: Properties APIs are alpha release (as of Feb 2017). Specification of APIs may change without notice.
Properties API
Dropbox API and Dropbox Business API provide store properties of files or folders. These properties are not displayed on desktop, mobile and web. Properties APIs are designed for application which integrate with Dropbox Business. Here are possible use cases.
- Store security policies for each files/folders.
- Store approval status of documents.
- Store document ID which issued from other CMS.
Properties template
Before storing properties of files/folders. You need to create Properties template in Dropbox Business team. To perform properties template operation, application must have “Team member file access” token. See more detail about auth type at Access Type.
Properties template can have multiple fields. Field can have single string value.
Here are APIs for Properties template. No method for delete template. Applications should maintain properties template id. Because you can create same name properties template. Template name is just for human friendly purpose.
Here is example of list existing templates:
templates = client.team_properties_template_list()
for t in templates.template_ids:
template = client.team_properties_template_get(t)
print "Template Id: %s" % t
print "Template Name: %s" % template.name
print "Description: %s" % template.description
for f in template.fields:
print "Field[%s] Description[%s]" % (f.name, f.description)
Store/retrieve properties of files/folders
To retrieve properties of file/folder, use /files/alpha/get_metadata. For retrieve properties, specify template id in include_property_templates attribute.
To store properties of file/folder, use /files/properties/add or /files/properties/overwrite.
Code sample
Here is complete code sample of use case of properties APIs. This sample expect to store security policy and levels for each files. This sample code using latest Dropbox Python SDK.
import dropbox
from dropbox.files import PropertyGroupUpdate
from dropbox.properties import PropertyFieldTemplate, PropertyType, PropertyField, PropertyGroup
# Dropbox Business Team file access token
DROPBOX_TEAM_FILE = ''
def list_more_files(client, cursor):
"""
:type client: dropbox.Dropbox
:type cursor: str
:rtype: list[dropbox.files.Metadata]
"""
chunk = client.files_list_folder_continue(cursor)
if chunk.has_more:
return chunk.entries + list_more_files(client, chunk.cursor)
else:
return chunk.entries
def list_files(client, path):
"""
:type client: dropbox.Dropbox
:type path: str
:rtype: list[dropbox.files.Metadata]
"""
# Set recursive=False because files under shared folders are not listed.
# call traverse_files for extract files recursively
chunk = client.files_list_folder(path, recursive=False)
if chunk.has_more:
return traverse_files(client, chunk.entries + list_more_files(client, chunk.cursor))
else:
return traverse_files(client, chunk.entries)
def traverse_files(client, entries):
"""
:type client: dropbox.Dropbox
:type entries: list[dropbox.files.Metadata]
:rtype: list[dropbox.files.Metadata]
"""
all = []
for f in entries:
all.append(f)
if isinstance(f, dropbox.files.FolderMetadata):
all += list_files(client, f.path_lower)
return all
def list_more_members(client, cursor):
"""
:type client: dropbox.DropboxTeam
:type cursor: str
:rtype: list[dropbox.team.TeamMemberInfo]
"""
chunk = client.team_members_list_continue(cursor)
if chunk.has_more:
return chunk.members + list_more_members(client, chunk.cursor)
else:
return chunk.members
def list_members(client):
"""
:type client: dropbox.DropboxTeam
:rtype: list[dropbox.team.TeamMemberInfo]
"""
chunk = client.team_members_list()
if chunk.has_more:
return chunk.members + list_more_members(client, chunk.cursor)
else:
return chunk.members
def show_properties_templates(client):
"""
:type client: dropbox.DropboxTeam
"""
templates = client.team_properties_template_list()
for t in templates.template_ids:
template = client.team_properties_template_get(t)
print "Template Id: %s" % t
print "Template Name: %s" % template.name
print "Description: %s" % template.description
for f in template.fields:
print "Field[%s] Description[%s]" % (f.name, f.description)
def find_properties_template_id_by_name(client, name):
"""
:type client: dropbox.DropboxTeam
:type name: str
:rtype: str | None
"""
templates = client.team_properties_template_list()
for t in templates.template_ids:
template = client.team_properties_template_get(t)
if template.name == name:
return t
return None
def audit_file(client, template_id, file):
"""
:type client: dropbox.Dropbox
:type template_id: str
:type file: dropbox.files.FileMetadata
"""
print "Auditing file: %s" % file.path_display
meta = client.files_alpha_get_metadata(file.path_lower, include_property_templates=[template_id])
if isinstance(meta, dropbox.files.FileMetadata) and meta.property_groups is not None:
for p in meta.property_groups:
if p.template_id == template_id:
for field in p.fields:
print "File[%s] Security Policy: %s = %s" % (file.path_display, field.name, field.value)
# Mark as Confidential for every '.pdf'
if file.path_lower.endswith('.pdf'):
print "Updating security policy: %s : template_id=%s" % (file.path_display, template_id)
level_field = PropertyField('Level', 'Confidential')
prop_group = PropertyGroup(template_id, [level_field])
client.files_properties_overwrite(file.path_lower, [prop_group])
def audit_member(client, template_id, member):
"""
:type client: dropbox.Dropbox
:type template_id: str
:type member: dropbox.team.TeamMemberInfo
"""
print "Auditing files of member: %s" % member.profile.email
files = list_files(client, "")
for f in files:
if isinstance(f, dropbox.files.FileMetadata):
audit_file(client, template_id, f)
if __name__ == '__main__':
client_team = dropbox.DropboxTeam(DROPBOX_TEAM_FILE)
# List existing properties template
show_properties_templates(client_team)
# Lookup template named 'Security Policy'
tmpl_name = 'Security Policy'
tmpl_desc = 'These properties describe how confidential this file is.'
tmpl_field_level_name = 'Level'
tmpl_field_level_desc = 'Level can be Confidential, Public or Internal.'
security_policy_template_id = find_properties_template_id_by_name(client_team, tmpl_name)
# Add template if not exist
if security_policy_template_id is None:
fields = [
PropertyFieldTemplate(tmpl_field_level_name, tmpl_field_level_desc, PropertyType.string)
]
security_policy_template_id = client_team.team_properties_template_add(tmpl_name, tmpl_desc, fields)
print security_policy_template_id
# Audit member files
members = list_members(client_team)
for m in members:
# Create client as user
c = client_team.as_user(m.profile.team_member_id)
audit_member(c, security_policy_template_id, m)