JJUG CCC 2025 Fall - Lightning Talkで話してきました
26th November 2025先日JJUG CCC 2025 Fallに参加してきました。また今回は十数年ぶり(記録が正しければ最後は2013年のJJUG CCC 2013 Fall)にLightning Talk (LT)で話をしてきました。 LTではあまり時間がありませんでしたので、その内容をこのブログで少し注釈付きで紹介したいと思います。
ITの話題で言うと、2025年はまさにAIエージェントの年と言っていいと思います。流れに乗って4月ごろからだったとおもいますがCursorやClaudeなどさまざまなエージェントを試し始めましたが、 エージェントに課金をする一方、まだ一円の儲けにもなっていません😅
いまはだいたい週に5億トークンぐらい使ってコードを書いていますので比較的ヘビーユーザーだと自認しています。 ですからエージェントにせめてたくさん働いてもらおうと言うのがこのLTでのテーマです。

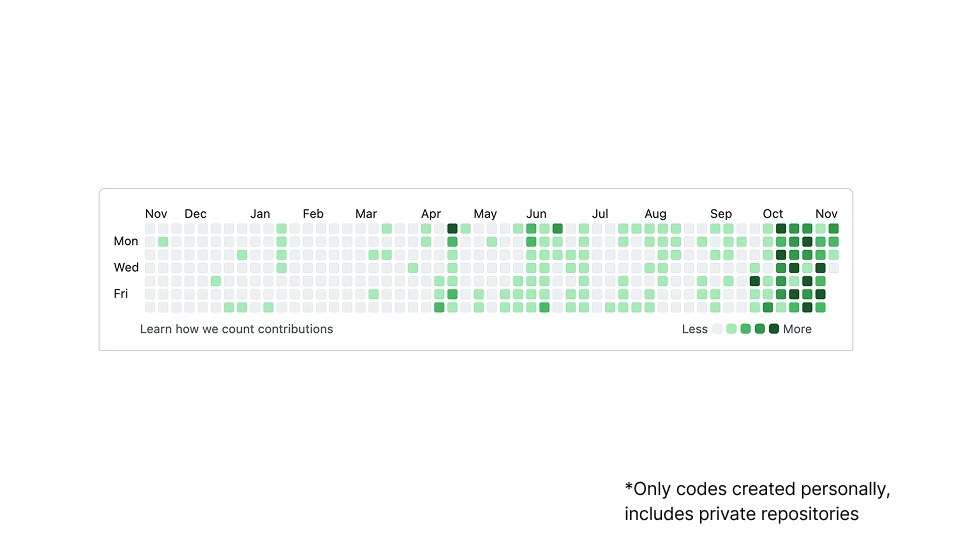
AIエージェントを使うようになってから劇的にコードを多く書くように(書くように指示するように)なりました。 次のスライドはプライベートレポジトリを含むGitHubでのアクティビティを図示したものですが、2025年4月から急激にアクティビティが活発になり、 10月からは劇的にあがっていることがご覧いただけます。
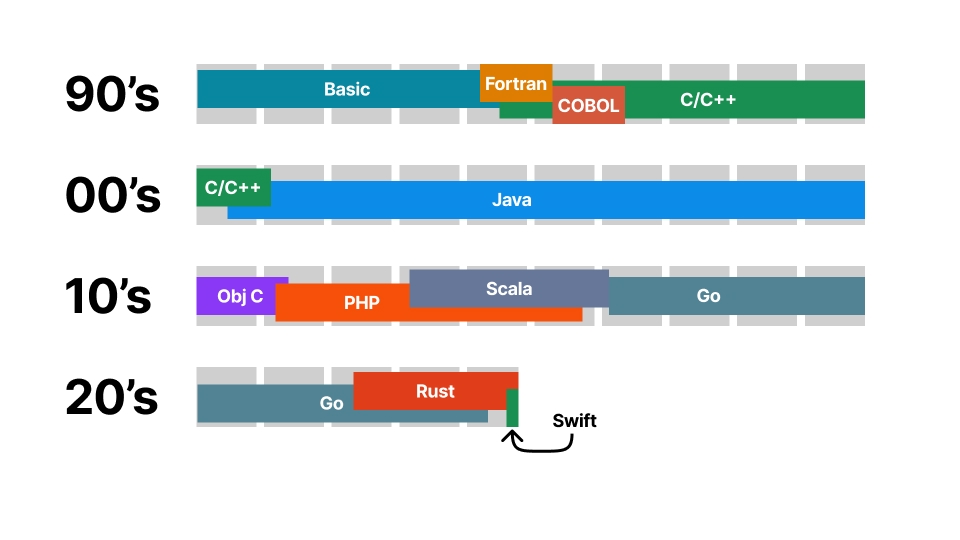
記憶を頼りに大まかに自分が今まで使ってきたプログラミング言語の変遷をまとめてみました。 これを見ると、Javaをやっていたのは15年前ぐらいがピークで、JJUGでの登壇が最後13年前というのもよくわかります。 そして最近はRustおよびSwiftを書いていますが、Swiftに至ってはこの登壇時点でまだ経験は6週間ほどです。
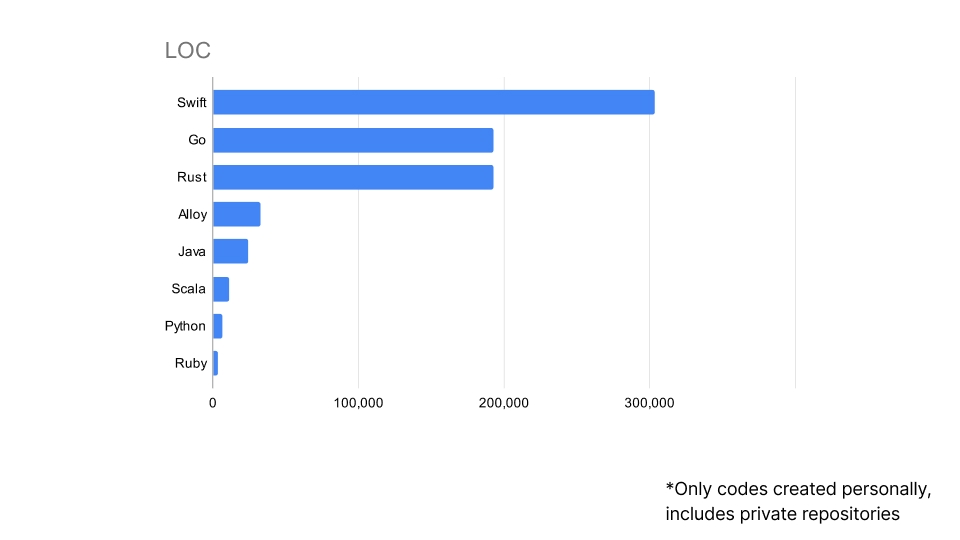
次のグラフは個人GitHubレポジトリをすべてcloneして、言語ごとにコード行数をカウントしたものです。 このレポジトリに仕事としてつくったものは含まれていませんので、実際に関わったものという意味ではJavaやPHPなどはもっと多いのですが、直近12〜13年程度は仕事では ほぼコードを書いていませんので概ね12〜13年の傾向としては、自分の作ったコード全体を示しているものと考えられます。
それでも、わずか6週間ほどで作ったSwiftによるコードが他のどの言語のものよりも多くなっています。
これはもちろん、AIエージェントの登場によるものです。
Rustもグラフでは20万行弱ありますが、おおよそ18万行程度はAIエージェントによるものです。 9年ほどかけて作ったGoのプロジェクトを数週間で軽く抜き去るようなインパクトがありました。 コード行数だけでなく、コミット数など他の指数をみても同様に圧倒的な差があります。

AIエージェントでなんでも!と言いたいところですが、AIエージェントがまだ持っていない機能もあります。
AIエージェントとプログラマーを比べれば、コードの記述や調べ物に関してはもう人間のプログラマーでは太刀打ちできない性能差があると言っていいと思います。
設計能力、複数コンポーネントをまたがる複雑なワークフローといったまだまだAIエージェントでは対応が難しい分野もありますがある程度仕様が決まったコードを書く、テストを書くといったときに、 もはやAIエージェントを使わないという選択肢を取れないレベルの経済的差が生まれています。
調べ物もそうですね。Web検索も複数あっという間に実施してくれますし、MCPなどを通じて社内レポジトリを検索ということもできますから、人間が一つずつ検索サービスにいくつか キーワードを試行錯誤するということと比べると比べ物にならないスピードの違いがあります。
これも同様に行間を深く読み解くといったようなことはAIエージェントには難しいですが、API仕様など意味がはっきりしたものを調べて、次のタスクに反映するということでは人間には勝ち目はないぐらいの違いがあります。

一方で、道具の面で見てみるとAIエージェントとプログラマーでは執筆時点においてまだ大きな差があると思います。 ひとつはリファクタリング機能の利用(名前の変更や、安全な削除、メソッドシグネチャの変更など)やデバッガの利用です。
リファクタリングでたとえば、クラス名を変えたいという時に、AIエージェントはsed/awkなどのコマンドを使いテキストを置換で編集しようとします。 これはかなり誤操作も多く、同じクラス名/変数名で別パッケージ/文脈のものも書き換えてしまったり、継承などにより名称が異なる実装には変更が波及できないと言った課題があります。
デバッガも同様で、AIエージェントにできるのはprint()を使って変数をダンプするという操作を追記するぐらいです。 圧倒的に非効率ですしコードベースがprint()だらけになって汚染されてしまいます。

実際に、Pythonやsedを使って一括置換されてコードベースが大きく破壊されてしまったこともあるので、 「Pythonを使ってソースコード編集しないで」とプロンプトに入れていても、AIエージェントはPython大好きですので😅 やらないでといった直後にもPythonで一括置換を試みてくれたりします。

これはプロンプトの作り方の問題もあります。人とコミュニケーションするときには、 理由や背景の説明、誤解を丁寧に解消すると言った努力が大事です。 また「もっとこうすればいいよ」というような相対的な表現を使うことが多いです。

正確性に欠けますがイメージとしてAIの動きを説明します。 LLMなど多くのAIはプロンプトをベクトルに変換して処理します。プロンプトで指示されたベクトルに続く答えを生成していると考えてください。
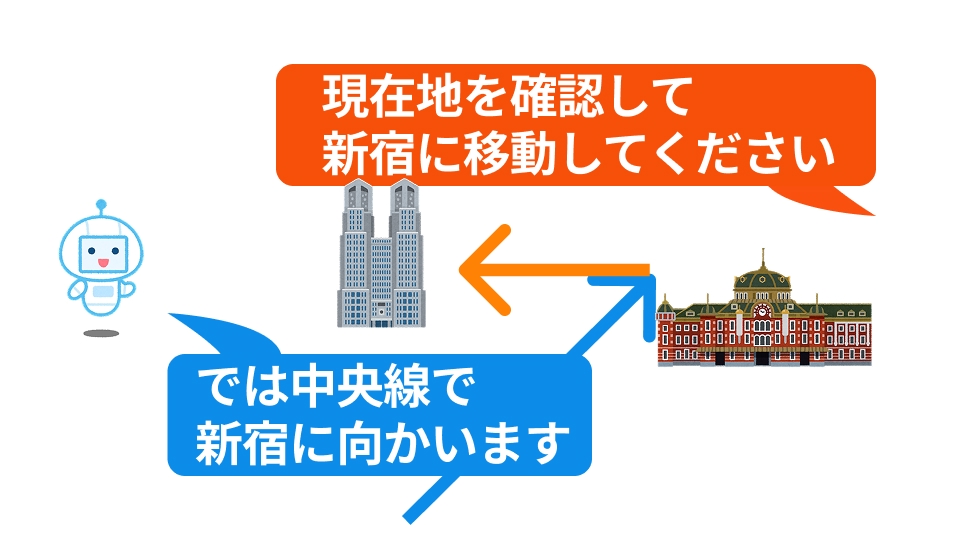
この前提において、AIとの会話において相対的な表現は危険な場合があります。 たとえば東京駅から新宿駅に移動したいとします。 東京駅からみて新宿は西方面ですから、「もう少し西の方に移動してください」というようにプロンプトで指示したとします。
これらのプロンプトはすべてベクトルに変換されて方向と強さが決められるのですが、 時間や空間の把握は現在のAIはあまり得意ではありませんので、「どのぐらい西なのか」という距離をうまく把握できていません。
これまでの会話の中で大阪から東京にきて、そこから新宿に行こうとしている会話の中で「もう少し西へ」といったら極端な話、 「大阪は東京の西にある」という連想から「大阪経由で新宿に向かいます」と突拍子も無い答えを返してしまう場合があります。
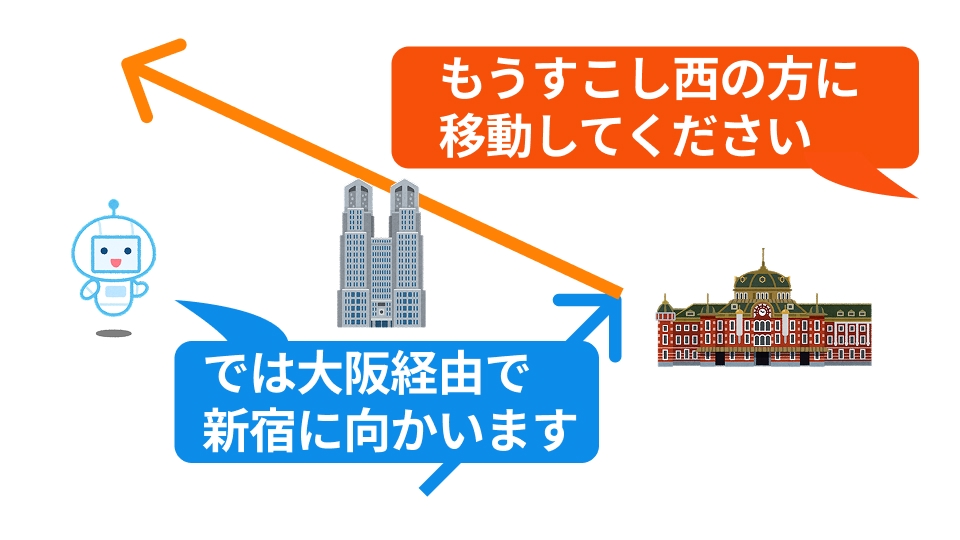
前述のような誤解を避けるために、AIに指示を出す時には絶対的な指示をしなるべく余計な情報を与えないことが肝心です。 東京駅から新宿駅の例でいば、「現在地を確認して新宿に移動してください」という指示をだせば、AIがいま東京駅にいるということを認識していなくても、 ではまず現在地を調べようというタスクを作って実行してから次のタスクに移ってくれますから、意図した通りに動作しやすいです。
大規模言語モデル(LLM)などのAIではコンテキストと呼ばれるメモリ領域のような働きの機能があります。 このコンテキストの節約は非常に重要です。特に指示はなるべく短く簡潔に、誤解のないように磨き上げる必要があります。
AIエージェントで使われる言語モデルだと25万〜100万トークンといったかなり大規模な領域がありますから、いろいろと節約しなくても良いと考えられるかもしれません。 しっかりと閾値を検査しているわけではないのですが、コーディング規約などAGENTS.mdのようなエージェントへの指示書で20〜30程度のルールを定義していても、 実際に覚えているなと感じるのは数個程度ではないかと思っています。 ですから、コードはたくさん読み込めるのですが、それを行動に移す時にはかなり限定的なルールを複数回に分けて指示する方が確実です。
たとえば(1) DDDをつかって設計し、(2) すべてイミュータブルに書いて欲しい、(3) print()は使わず規定のロガーを使って欲しい。 という場合があったとします(実際にはこれが数十個必要になりますが例のため3つにしておきます)。
(1), (2), (3)を一度に指示した時には一つぐらい忘れてしまって、print()をたくさん生成してしまうということは頻繁に発生してしまいます。
これを設計を(1)を使って実行してください。(2)を使って実装してください、(3)のようにprint()がないか確認してください。と3回に分ければかなり精度良く思った通りのコードに近づきます。
また意図しないベクトルが入らないように雑音となるような指示をなるべく避けるといいでしょう。 たとえば「XXXはやらないで」といったような否定的な表現よりは「YYYしてください」という表現で肯定的にする方が経験上うまくいきます。
そして最後に人とのコミュニケーションでは相対的にしていたコミュニケーションを、AI向けには冗長でも絶対的コミュニケーションにすると良いでしょう。

AIへの指示ですが、AIが意図通り指示を解釈してくれないとイライラしてしまいます。 そうしたイライラをさけるには、定型文を準備しておくと良いでしょう。
定型文を選ぶだけですから感情を入れずに指示できますし、何より何度も同じような指示を書くのは面倒なので定型文+少し微修正というやり方がいいです。
スペック駆動開発をされている場合は、スペック駆動のワークフローを説明するプロンプトをいくつか局面ごとに準備しておくといいでしょう。 今試しているのはDESIGN (デザインドキュメントだけ書く) -> PLAN (タスク一覧と依存関係だけを書く) -> CRAFT (コードを書いたりテストを実施) という3つのフェーズで回すスプリントサイクルです。
定型文としてはDESIGN -> PLANへ移ってくださいというような指示や、PLAN -> DESIGNに戻ってくださいというような指示をそれぞれ指定してあり、意図しないコードが生成された時にはすぐにDESIGNに戻って設計を修正するなどしています。
さらには現状のこのルールを守って続けてくださいというプロンプトも非常に便利で良く使います。たとえば、DESIGNフェーズならデザインを続けてください。というような指示です。

MCPを使えばリファクタリングやデバッガの利用などできそうですが、この発表時点ではまだ実験的で安定的にできそうな印象でしたのでこれはまだもう数ヶ月待たなければいけないかもしれません。 ですので、AIエージェントを使った開発はまだ十分モダンな開発ツールを使いこなせている生産性の高い状態とは言い難い状況です。

このため今実施している直近の開発プロジェクトではログの強化を先に実施しています。 これはGoで書いていたwatermint toolboxの時から利用している手法で、AIエージェントに限らず人間がログを見る時にもかなり有効でした。
構造化されていないログたとえば、次のようなログがあったとします。基本はgrepなどを使って、WARN, ERRORといったエラーレベルで絞り込み、モジュール名などで絞り込んでいきますがなかなかに冗長ですし、特定条件のログだけを抽出するというのは意外に面倒です。 タイムスタンプについても、2025-11-26 22:15:02〜2025-11-26 22:15:15区間のみ欲しいというような取得も難しいです。
2025-11-26 22:15:01,234 INFO com.example.app.Main - Application started. version=1.2.3
2025-11-26 22:15:02,017 DEBUG com.example.service.UserService - Loading user. id=42
2025-11-26 22:15:02,056 WARN com.example.service.UserService - User not found. id=42
2025-11-26 22:15:02,059 ERROR com.example.web.UserController - Failed to handle request /users/42
Goで書いていたwatermint toolboxのログは今では独自実装を使っていますがもともとは、Uberが開発しているuber-go/zapのAPIを参考にしています。
{"level":"info","ts":1732636801.234,"logger":"http.server","msg":"request received","method":"GET","path":"/api/v1/users/42","request_id":"8c1d7e0f4d8b4e1b","remote_ip":"203.0.113.10","user_agent":"Mozilla/5.0","latency_ms":1.23}
{"level":"debug","ts":1732636801.245,"logger":"service.user","msg":"loading user","user_id":42,"cache_hit":false,"trace_id":"a7c9b3b9c2f9404e8e3f0f5c2c716c3c"}
{"level":"warn","ts":1732636801.251,"logger":"service.user","msg":"user not found","user_id":42,"error_code":"USER_NOT_FOUND","trace_id":"a7c9b3b9c2f9404e8e3f0f5c2c716c3c"}
{"level":"error","ts":1732636801.260,"logger":"http.handler","msg":"failed to handle request","method":"GET","path":"/api/v1/users/42","request_id":"8c1d7e0f4d8b4e1b","status":404,"error":"user not found_
JSON形式で上記のようなログになっていれば、jqなどのコマンドを使い warn, error のタイムスタンプ 1732636800〜1732636815 区間のみ取得というのもさほど難しくありません。 クエリを自分で作るのはなかなかに大変ですがAIエージェントまたはAIチャットに聞けばすぐに作ってくれます。
cat app.log \
| jq 'select(
.ts >= 1732636800 and .ts <= 1732636815
and
(.level == "warn" or .level == "error")
) | {ts, level, msg, user_id, error_code, trace_id}'
既存のログAPIでもし同様のことができるのであれば、かなりおすすめです。
ログフレームワークの変更や改変はかなり大変ですから、もし今のログフレームワークに追加的な設定で同等の出力ができるのであればという条件付きにはなりますが、非常にパワフルです。 なぜなら、これによりAIにログの検索からすべてお願いできるからです。

もしこれから新しくプロジェクトを始められたりする計画がある場合は、ログフレームワークもAI向けに設計し直されてからでもいいと思います。
実際に手元のプロジェクトではそのようにしました。ログになるべくトレースに近い文脈が残るようにAPIを設計し、AIエージェントにはそのログAPIを文脈が残るように使いなさいと指示を出します。 プログラマーが書くにはかなり冗長で面倒なコードですが、AIエージェントに全て書いてもらうのであれば面倒臭さはありませんし、なによりAIにログを見てもらうときの精度が上がるのはとてもお得です。
AIエージェントがデバッガーを使える時代になっても、デバッガーが接続できない環境やシチュエーションというのは幾つでもありますから、ログの充実は今後かなり効いてくると思います。

前述の通り、jqなどのツールを使ってログを検索してもらうようにし、AIにはそのコマンドを使うように指示すればあとは複雑なクエリでもすぐに作ってくれます。
手元のプログラムではCLIアプリの場合、CLIフレームワークにログ取得およびログクエリフレームワークを取り込みjq互換のクエリを実行できるようにし、さらにプログラム終了時にはこのUUIDでクエリできるよと説明までつけているので、 AIエージェントにエラー訂正を頼むときはその行を含む出力をコピペすれば良いだけですから指示の手間が大幅に省けます。

このようにいくつかテクニックを適用していけばAIエージェントを使った開発はストレスなくスムーズにすすめられます。 まだまだたくさんの改良を施して、またAIエージェントを開発している各社の進展を見守りながら最も効率の良い開発を目指して、AIエージェントに支払っている費用が回収できるように使いこなしたいですね。

それではHappy Hacking!
発表の機会をくださったJJUG運営の皆さん、LTに参加して発表を聞いてくださった皆さん、いつもJJUGの発表資料をまとめてくださるYujiSoftwareさんありがとうございました。