Go Programming Trial and Error - Developing a command line tool for Dropbox
23rd July 2020I started building my first Go program in early 2016. I introduced it once on the blog in late 2017. I’d like to introduce the differences from the time I introduced it, and also what I’ve tried and achieved with the Go language after about 4 years of practice, as a reminder. In this article, I’ll show you how I designed and implemented the language in the first part of this article.
watermint toolbox

The project I spend the most time on in creating the Go program is a project called watermint toolbox. This is a tool that allows you to manage files, permissions, etc. in Dropbox and Dropbox Business from the command line. For example, if you want to list the group members on your team, you can run the following
watermint toolbox 71.4.504
==========================
© 2016-2020 Takayuki Okazaki
Licensed under open source licenses. Use the `license` command for more detail.
Testing network connection...
Done
Scanning: Developer Inc のメンバー全員
Scanning: Okinawa
Scanning: Osaka
Scanning: Tokyo
group_name group_management_type access_type email status surname given_name
xxxxxxxxx Inc のメンバー全員 system_managed member xxx.xxx@xxxxxxxxx.xxx active 杉戸 宏幸
xxxxxxxxx Inc のメンバー全員 system_managed member xxx.xxxx@xxxxxxxxx.xxx active 藤沢 由里子
xxxxxxxxx Inc のメンバー全員 system_managed member xxx.xxxx@xxxxxxxxx.xxx active 江川 紗和
xxxxxxxxx Inc のメンバー全員 system_managed member xxx.xxx@xxxxxxxxx.xxx active 正木 博史
xxxxxxxxx Inc のメンバー全員 system_managed member xxx.xxxxx@xxxxxxxxx.xxx invited
xxxxxxxxx Inc のメンバー全員 system_managed member xxx.xxx@xxxxxxxxx.xxx active Dropbox Debugger
xxxxxxxxx Inc のメンバー全員 system_managed member xxx.xxx@xxxxxxxxx.xxx active 里咲 広瀬
xxxxxxxxx Inc のメンバー全員 system_managed member xxx.xxx@xxxxxxxxx.xxx active 関本 重信
The report generated: /Users/xxxxxxxx/.toolbox/jobs/20200723-101557.001/report/group_member.csv
The report generated: /Users/xxxxxxxx/.toolbox/jobs/20200723-101557.001/report/group_member.json
The report generated: /Users/xxxxxxxx/.toolbox/jobs/20200723-101557.001/report/group_member.xlsx
(People’s names are pseudonyms, some output results have been replaced.)
The result report is output to standard output and the details are saved to a file in CSV, xlsx or JSON format. You can select Markdown or JSON as the output format for the standard output, but if you select JSON, you can easily extract the group name and email address from the above mentioned output and convert them to CSV by using the jq command.
% tbx group member list -output json | jq -r '[.group.group_name, .member.profile.email] | @csv'
"xxxxxxxxx xxx のメンバー全員","xxx+xxx@xxxxxxxxx.xxx"
"xxxxxxxxx xxx のメンバー全員","xxx+xxxx@xxxxxxxxx.xxx"
"xxxxxxxxx xxx のメンバー全員","xxx+xxxx@xxxxxxxxx.xxx"
"xxxxxxxxx xxx のメンバー全員","xxx+xxx@xxxxxxxxx.xxx"
"xxxxxxxxx xxx のメンバー全員","xxx+xxxxx@xxxxxxxxx.xxx"
"xxxxxxxxx xxx のメンバー全員","xxx+xxx@xxxxxxxxx.xxx"
"xxxxxxxxx xxx のメンバー全員","xxx+xxx@xxxxxxxxx.xxx"
"xxxxxxxxx xxx のメンバー全員","xxx+xxx@xxxxxxxxx.xxx"
(Some of the output results have been replaced.)
It also implements more than 100 other commands such as file upload, list of shared links, add and remove members, and more. Please refer to the README for more details on what you can do.
Requirements and constraints
The purpose of this tool development is to improve operational efficiency and solve issues in using Dropbox Business and Dropbox.
Dropbox has released a script that solves a common issue in the repository called DropboxBusinessScripts. On the other hand, this project is about being as easy to implement as possible to solve our goals, and in particular, not requiring additional libraries or configuration to use the tool, which was the main reason for choosing Go.
Since this program runs on a PC, its usage and messages should be easy to understand, and if a problem occurs, you should be able to find out the situation from a set of log files without having to ask for detailed information.
This project was a personal development project, there is mainly time resource constraints. There were times when I could develop a certain amount of code at a time, and other times when I didn’t write any code for several months. When I don’t write anything for a few months, the structure of the code disappears from my mind, so I had to suffer a lot of duplication and redoing.
The main requirements and constraints that I note from the above requirements and constraints are as follows. The reasons for each will be discussed below.
- distribution in a single binary (both executable and licensing point of view)
- Log every process to increase traceability
- Prioritize development productivity over CPU time
More recently, I have been paying attention to the following points as additional requirements
- Internationalization (Japanese and English)
- To save time, documents are basically auto-generated
- Do not overwhelm the disk with log files and intermediate files.
- Memory consumption should generally be kept to under a few hundred MB.
- Improved durability and optimized execution speed
I will recall how this project has been walked through with the above requirements and constraints in mind.
Selecting SDKs for APIs
At the time of writing, watermint toolbox has GitHub and Gmail related commands as well as Dropbox and Dropbox Business. These APIs are available as SDKs, so using these SDKs is more productive from the point of view of development productivity. I used to use SDKs in early stage of development, but I don’t use any SDKs including official and unofficial ones at this moment except OAuth2 implementation.
The SDK has both useful aspects and constraints. In particular, the constraints include the following
- In many cases, the log output cannot be changed in granularity or output method due to proprietary implementation.
- Error handling is blacked out
- There is a time lag between API updates and SDK updates.
Here’s a little more about each.
Log
This is not limited to the SDK, and it’s not limited to the Go language, but it’s quite difficult to unify the control to suppress the output or to get the trace log for debugging because each library logs to its own heart’s content. If you use the standard log library, you can switch the log output destination, but in the worst case, you can’t control the output by using fmt.Printf. So you can send a pull request, give up, or create your own library. This time, I made the REST API framework from SDK for the reasons mentioned later, so I decided to make it by myself.
For log processing I used seelog in the beginning, but now I use zap wrapped in my own library. I think the main reason was that we wanted to change the JSON to a JSON that was easy to process in.
Instead of using zap as it is, I wrapped it in my own library for additional processing such as log rotation, compression, etc., and also for insurance in case I have to switch to a different log library at another time. As you know, it’s quite a hassle to switch log libraries.
Error handling is black boxed
In exception handling in languages with relatively strong types such as Java, classes are defined for each exception (e.g. AuthenticationException for authentication errors, IOException for network I/O problems, etc.) and the code that receives the exceptions handles them. You can determine and change the behavior.
You can define each error type in Go as well, but in some libraries, the entire process is rounded up into a string. This is probably more a cultural part of the library implementation than a language specification; some libraries throw everything as an Exception or RuntimeException in Java as well. However, as I have a long experience with Java, I feel that Go is more likely to suffer from this kind of problem.
For example, a case that still bothers me a bit is the golang/oauth2 Pull Request, errors: return all tokens fetch related errors as claimed in structured, where the errors are rounded to a string. Then it’s bit difficult to determine is the error retriable or not. Since this Pull Request seems to be neglected for more than a year, it’s quite difficult to decide whether to give up on Google’s implementation or to accept this as a specification and use it with a fixed version.
Other than this, I also experienced a black box error handling that made it look like a server error, even though it was a parameter error, and I wasted a lot of time trying to figure out what was going on. The accumulation of this wastage was a major driving force behind the plan to de-SDK.
Since the current watermint toolbox is implemented using my own REST API framework instead of using the SDK, all API requests and responses, except for those around OAuth2, are individually logged in JSON format, not to mention the trace log output during processing. For this reason, the reproducibility is high and it is possible to quickly determine whether the error is a parameter problem or a network problem.
Related commands have been added to improve productivity, for example, the API request and response of the last command executed can be output in JSON format. jq command makes it easy to extract the request with response code 409. Note that the token string is automatically replaced with
% tbx job log last -kind capture -quiet | jq
{
"time": "2020-07-23T11:34:58.820+0900",
"msg": "",
"req": {
"method": "POST",
"url": "https://api.dropboxapi.com/2/team/get_info",
"headers": {
"Authorization": "Bearer <secret>",
"User-Agent": "watermint-toolbox/`dev`"
},
"content_length": 0
},
"res": {
"code": 200,
"proto": "HTTP/2.0",
"body": "{\"name\": \"xxxxxxxxx xxx\", \"team_id\": \"dbtid:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx\", \"num_licensed_users\": 10, \"num_provisioned_users\": 8, \"policies\": {\"sharing\": {\"shared_folder_member_policy\": {\".tag\": \"anyone\"}, \"shared_folder_join_policy\": {\".tag\": \"from_anyone\"}, \"shared_link_create_policy\": {\".tag\": \"default_team_only\"}}, \"emm_state\": {\".tag\": \"disabled\"}, \"office_addin\": {\".tag\": \"disabled\"}}}",
"headers": {
"Cache-Control": "no-cache",
"Content-Type": "application/json",
"Date": "Thu, 23 Jul 2020 02:34:58 GMT",
"Pragma": "no-cache",
"Server": "nginx",
"Vary": "Accept-Encoding",
"X-Content-Type-Options": "nosniff",
"X-Dropbox-Request-Id": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"X-Envoy-Upstream-Service-Time": "77",
"X-Frame-Options": "SAMEORIGIN",
"X-Server-Response-Time": "71"
},
"content_length": 400
},
"latency": 384840087
}
(Some of the output results have been replaced.)
There is also a command that can be used to process this output and display the execution options with the curl command. (Note: The latest release, 71.4.504 at the time of this writing, has a bug that prevents it from working. Please wait for release 72 or later.)
% tbx job log last -kind capture -quiet | tbx dev util curl
watermint toolbox `dev`
=======================
© 2016-2020 Takayuki Okazaki
オープンソースライセンスのもと配布されています. 詳細は`license`コマンドでご覧ください.
curl -D - -X POST https://api.dropboxapi.com/2/team/get_info \
--header "Authorization: Bearer <secret>" \
--header "User-Agent: watermint-toolbox/`dev`" \
--data ""
HTTP/2 200
cache-control: no-cache
content-type: application/json
date: Thu, 23 Jul 2020 02:34:58 GMT
pragma: no-cache
server: nginx
vary: Accept-Encoding
x-content-type-options: nosniff
x-dropbox-request-id: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
x-envoy-upstream-service-time: 77
x-frame-options: SAMEORIGIN
x-server-response-time: 71
{"name": "xxxxxxxxx Inc", "team_id": "dbtid:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx", "num_licensed_users": 10, "num_provisioned_users": 8, "policies": {"sharing": {"shared_folder_member_policy": {".tag": "anyone"}, "shared_folder_join_policy": {".tag": "from_anyone"}, "shared_link_create_policy": {".tag": "default_team_only"}}, "emm_state": {".tag": "disabled"}, "office_addin": {".tag": "disabled"}}}
(Some of the output results have been replaced.)
The API logs are currently also used for automated testing. I can replay the old API logs for various business logic to ensure that the business logic has not been affected by refactoring of the framework. I also have a command to anonymize log information for the preparation of data for testing, to improve efficiency.
There is a time lag between API updates and SDK updates.
When new APIs are added or parameters are added, it takes a certain amount of time for the SDK to keep up with those changes; in the case of the Dropbox API and the official SDK, the time lag is relatively short since the SDK is generated using the API’s DSL, called stone.
SDK for Go is positioned as unofficial, at the time of writing there are eight months’ worth of differences between the latest API and the one in use.
Whether or not to allow for this difference depends on your requirements, but in the watermint toolbox, I decided not to use the SDK because we wanted to try out the latest APIs easily.
One of the big advantages of using the SDK is that you don’t have to do the data structure definition yourself. As I’ve felt in the past when I was building tools to call REST APIs in Java and Scala, without using the SDK, most of the code was for defining data structures and mapping them to our own domain model. While the implementation work is monotonous and not very fun, I try to avoid this mapping work as much as possible because if I get it wrong, I get stuck in it. Again, in reinventing the REST API framework, I tried to keep the data structure definition to a minimum.
The following structure is designed to handle shared link data in the Dropbox API, but we decided to define only the minimum number of fields necessary to handle it in this tool.
type Metadata struct {
Raw json.RawMessage
Id string `path:"id" json:"id"`
Tag string `path:"\\.tag" json:"tag"`
Url string `path:"url" json:"url"`
Name string `path:"name" json:"name"`
Expires string `path:"expires" json:"expires"`
PathLower string `path:"path_lower" json:"path_lower"`
Visibility string `path:"link_permissions.resolved_visibility.\\.tag" json:"visibility"`
}
The first defined raw is the raw data returned by the API, and the following fields, such as Id and Tag, are automatically retrieved from path information in JSON, such as path:"id" and path:"\\.tag".
Fields are defined in this way for items of high interest to users, such as shared link names, URLs, expiration dates, etc., that you want to output as reports, and other information is handled as JSON data only. Reports are output in three formats: CSV, xlsx, and JSON, but only these defined fields are output to CSV/xlsx. If you need information not included here, you can use the jq command to extract it from the JSON output.
In order to easily retrieve only the information necessary for business purposes, it is sufficient to refer to CSV and xlsx format reports, and the data necessary for automation, such as id information, can be retrieved from the JSON format. By using these loose data structure definitions, the program can be used with almost no impact when fields are added to the API.
Addressing requirements and constraints
We will now look back again at how we have addressed the requirements and constraints mentioned above.
Single binary distribution
Being able to distribute a tool as a single binary is a very important theme for such a tool. If it is a tool that runs on my own PC or server, I can relax the library and OS requirements to some extent, but it is very important to support a wide range of OSs because it is a tool that runs on various users’ environments. The mechanism of single binary distribution is not limited to the Go language, but I think that the library group and the richness of the IDE have the advantage of being a certain pioneer in this field.
Although the watermint toolbox is licensed under the MIT license, it is linked with libraries under various other licenses. When selecting libraries, we mainly select the compatible BSD and Apache v2 licenses, and take care not to mix GPL licenses.
Log every process to increase traceability
Problems that occur in a user’s environment are often difficult to reproduce in my own environment, partly because of differences in the PC environment, and partly because of differences in the configuration, environment and size of the Dropbox or Dropbox Business where the API is used. For this reason, the logs are all output in the trace level. The log size is quite inflated, but I allow for the log size because priority to the time. Also, as described later, I’m currently using compression and log rotation to prevent the logs from overwhelming the disk.
Also, to make it easier to analyze the logs, the current version outputs all logs in JSON format (more precisely, JSON Lines format), to make it easier to extract errors and memory usage statistics by combining commands such as grep and jq.
For example, by logging the last command executed and processing the results with jq, you can get time by time heap usage statistics, as shown below. Such statistics can be useful in identifying the cause of the problem, since detailed data, such as memory profilers, are difficult to obtain in the user environment.
% tbx job log last -kind toolbox -quiet | jq -r 'select(.caller == "es_memory/stats.go:33") | [.time, .HeapAlloc] | @csv'
"2020-07-23T12:34:08.549+0900",104991184
"2020-07-23T12:34:13.548+0900",105058744
"2020-07-23T12:34:18.550+0900",111987752
Prioritize development productivity over CPU time
The watermint toolbox is a program that mainly makes API calls, processes the results and outputs them. The execution time ratio is relatively high in API processing wait time, and the ratio of CPU time is not high and can be almost negligible. Therefore, the programming style has changed in the last four years to be in line with it.
The biggest change is that I’ve been using Scala for a while now, and I’ve been trying to make my implementation functional and immutable. I’ve already failed to some extent in this endeavor, but I’ll talk about that later, but let’s start with the details.
I don’t remember where I read it, but I think it said that the idea of Go is that we should not hide the complexity of the process in functions and so on. For example, when I need to sum the fields of some structure, my experience is that I usually think of cutting them out as functions to make them easier to reuse and test. Well, it’s not that hard to do.
type File struct {
Name string
Size int
}
func TotalSize(files []File) (total int) {
for _, file := range files {
total += file.Size
}
return
}
This works and there is no problem at all, but the above claim is that when you call TotalSize(), that does not tell whether it’s O(N) or O(N2) processing, but the caller can’t understand how much processing order is hidden behind it, so you should inline this kind of simple processing I think the argument was something like this. I think it was a superstition in the early days of my introduction to Go. It may be a superstition that I made a mistake at the beginning of my introduction to Go.
type File struct {
Name string
Size int
}
func MyBizLogic() {
// ...
var folder1Total int
for _, file := range folder1Files {
folder1Total += file.Size
}
// ...
var folder2Total int
for _, file := range folder2Files {
folder2Total += file.Size
}
}
Naturally, the code would be less readable, and productivity was significantly reduced due to mistyping and lack of test coverage. If you really wanted to care about processing order, it would be much more effective to name your functions with Hungarian naming, like ONLOGNTotal() or ON2Total(). I was completely superstitious.
Now that I understand myself that this is a superstition (it took me a couple of years to do so…), it’s only natural that you’d want to do the same array and hash operations that you’ve always done in Scala or Ruby. It’s natural to want to do the same kind of array and hash operations that you normally do in Scala or Ruby.
I looked at some existing libraries and decided to use go-funk as a reference. go-funk makes full use of reflection to improve readability and productivity. As you can see in the Performance section of the project introduction, they don’t prepare functions for each type like ContainsInt() does.
I thought about using go-funk, but I decided to make my own to practice the Go language. The result is a library that looks like this. For example, you can define arrays a and b, and then extract the common elements.
a := es_array.NewByInterface(1, 2, 3)
b := es_array.NewByInterface(2, 3, 4)
c := a.Intersection(b) // -> [2, 3]
I thought I could make a library that is somewhat immutable and functional, but as I mentioned above “This attempt has already failed to some extent”, I ran into a wall in the language specification. The problem is the type information.
var folder1Files, folder2Files []File
// ... Getting folder1Files and folder2Files
// Convert from array to array interface for use in the library
folder1List := es_array.NewByInterface(folder1Files...)
folder2List := es_array.NewByInterface(folder2Files...)
// Extract the files common to folder1 and folder2
commonFiles := folder1List.Intersection(folder2List)
Now, this works to a certain extent, but the problem is that each time we deal with the resulting elements, we need to cast them.
commonFiles.Each(func (v es_value.Value) {
f := v.(File)
// Processing the element
})
Well, I’d say it’s not a problem, but while using the library makes it more efficient to some extent, it also increases the chance of a type exception at runtime, which is easy to solve in languages with strong types or type variables like Java and Scala, but difficult to solve in languages with weak types like Go. I guess.
sort.Strings() in the standard library, passing an array for each type will reduce type-related errors. On the other hand, this will only work if the number of elements in the array remains the same, and it won’t work if you want to extract common elements from the two arrays or join the two arrays as described above.
menu := []string{" Soba", "Udon", "Ramen" }
sort.Strings(menu) // The array size doesn't change before and after processing
For now, I’m thinking about using this library in my entire project while covering the problems with unit tests, but if I come up with another good idea, I’d love to incorporate it into my work.
Internationalization
The watermint toolbox has been used in many countries, including Japanese users. Initially, the toolbox was only available in English, but since last year, we have been able to provide a Japanese language version.
The translation memory software is OmegaT, with a plugin for the JSON data format.
There are a lot of libraries for internationalization, but I created them myself without thinking too much about it; I stored the message keys and translation text in JSON and switched the messages for display according to the language.
Now that I think about it, it may have been good to use go-i18n. go-i18n seems to use CLDR, and it seems to be able to handle differences of each language such as plural forms more finely. It may be worth trying to switch libraries at some point. Fortunately, I don’t think the switching cost is not so high because I don’t have deep implementation about internationalization.
To save time, documents are basically auto-generated
The most troublesome part of a personal project is the creation of the documentation. It takes a lot of time to create documents at the beginning, but it also takes some time to maintain them when the specifications change.
For this reason, the watermint toolbox automatically generates as much documentation as possible, including manuals. Although some explanations are missing, the ability to update the documentation in a comprehensive manner is a great advantage. It is not difficult to prepare manuals in the same format for multiple languages, as long as you have translated text.
However, automatic generation required several steps to be taken. Treating command specifications as programmatic data, extracting messages from the source code, detecting and reporting missing messages, generating update diffs for release notes, incorporating checks into the release process, and so on, I now have the ability to generate some readable manuals automatically.
The fact that command specifications can now be handled as data has been a nice side effect. Command specifications are stored in JSON format for each release, and this JSON makes it easier to extract, for example, a list of commands that take a CSV file as an argument.
% gzcat doc/generated/spec.json.gz | jq -r '.[] | select(.feeds | length > 0) | .path'
file dispatch local
file import batch url
group batch delete
member clear externalid
member delete
member detach
member invite
member quota update
member replication
member update email
member update externalid
member update profile
team activity batch user
team device unlink
team filerequest clone
teamfolder batch archive
teamfolder batch permdelete
teamfolder batch replication
Don’t overwhelm the disk with log files and intermediate files.
In order to improve the efficiency of the debugging process, I spent a relatively large amount of time on the log output part. On the other hand, operations on large folders and teams took longer to execute and the log sizes were not negligible. Sometimes exceeding 100 GB. For this reason, recent releases incorporate a mechanism to gzip the logs and divide them into smaller chunks, deleting the old logs when they exceed a certain size.
Also, if it deletes the logs in order from the oldest, important data such as startup parameters may be lost, so I had to devise a way to output those data to a different log.
Implementing the log compression and rotation process itself was not too difficult, but I spent a lot of time trying to improve stability on Windows. This is due to deadlocks in a multi-threaded environment. There were several issues, including deadlocking of mutexes and waiting for I/O processing that still deadlocked. The frequency of reoccurrence was about once every hour to a few hours, so fixing and confirming the fix was quite a challenge.
I don’t think the code is durable enough for all conditions, but I believe the probable deadlock is mostly resolved. In addition, the deadlock was generally reproduced in the following code when connecting to the debugger.
type LogWriter struct {
w io.Writer
m sync.Mutex
}
func (z *LogWriter) Write(data []byte) (n int, err error) {
z.m.Lock()
defer z.m.Unlock()
return z.w.Write(data)
}
Indeed, it’s possible that Write() itself could be deadlocked if it’s locked from the OS in some way. I haven’t researched the spec in detail, but that’s probably because I/O locking is more strict on Windows.
What you can see from the black box test is that when you select any text on a console, such as PowerShell, the scrolling locks and the standard output stops. On macOS and Linux, such a lock does not occur. I would like to investigate this issue in more detail if a similar issue occurs again.
Memory consumption should be generally kept to a few hundred MB.
If you use an external library, the memory consumption may be higher than expected. We have a solution for some of the libraries that use a lot of memory. I’ll introduce some concrete examples.
In addition to CSV and JSON, the watermint toolbox also provides the xlsx file format, which is used by Excel and others.
The CSV is enough for most cases, but if you try to read CSV with Japanese characters (UTF-8 encoding, no BOM) in Excel, Excel will not recognize the encoding correctly and the characters will be broken. You can add a BOM to the CSV side, but it will not be easy to use in programs that expect no-BOM. For this reason, I also support xlsx format output to avoid garbled characters in casual use.
Now the xlsx format is one of the Office Open XML, now standardized as ISO/IEC 29500. xlsx files are a collection of zipped files, and the files that contain the main data are made in the XML format.
Representing the spreadsheet in XML means that the entire spreadsheet needs to be expanded in memory once as a DOM or other XML tree. As the size of the spreadsheet grows, it uses proportionally more memory. Therefore, if you try to output the report in XML format, it will eat up the memory space proportionally according to the number of rows in the report. In some cases, this can cause an out of memory error and stop the process. As a countermeasure, the xlsx report is divided into separate files when the number of lines exceeds a certain number.
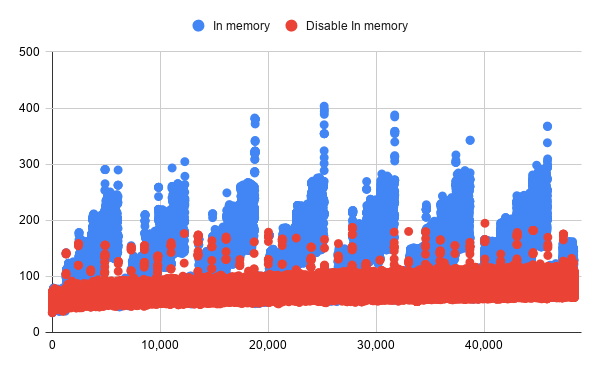
In addition to this, I also tuned the KVS, Badger. It use memory for caching, based on the number of data items. Again, the method of obtaining memory statistics from the log files was useful for long-term measurements with different parameters. The figure above shows the memory consumption trend for the two parameter settings.
Improved durability and optimized execution speed
Durability and execution speed are areas where there is still room for growth. In terms of fault tolerance, I have already implemented automatic retries when calling APIs, but I believe that there is room for improvement in error handling for the framework as a whole.
The watermint toolbox consists of commands, which are the core of the business logic, and the framework part that supports it. In most cases, the business logic part of the toolbox does not process errors returned by the API, and therefore, when an error occurs, it is returned to the upper framework.
func (z *List) Exec(c app_control.Control) error {
entries, err := sv_files.New(z.Peer.Context()).List(z.path)
if err != nil {
return err // return an error to the upper framework
}
// ... Subsequent processing
return nil
}
Network IO errors are handled by the REST API framework, and this is not a problem. But when retrieving a file list from a folder, is it necessary for the business logic that a different process is performed if the file does not exist, or is it an authentication error. I don’t know if this is an error or not, and I think it’s a bad idea to write the logic in various places.
Eventually I may settle again on the current form, but I may create a mechanism to explicitly separate what is handled by the framework from what is handled by the business logic, as there are attempts to implement try types, or to return on errors or to use panic().
There is still a lot of room for improvement in optimizing the execution speed. The current commands are programmed to be executed in multi-threads if they can be distributed to some extent, such as file uploads, folder permissions, etc. I don’t have to worry too much about it because the Go language has an environment for parallel processing such as goroutine and channels. I like the fact that it can be implemented.
On the other hand, if the execution time is longer than a few days, the overhead to reach the restart point becomes large, the intermediate file becomes bloated, and the progress is difficult to see. Therefore, it is time to consider introducing a processing framework that uses persistent asynchronous queues.
Summary
I have incorporated some of the development processes myself, such as the release process, as part of the tools, and our development efficiency is much better than it was four years ago. On the other hand, the Go language and the ecosystem surrounding it has allowed me to add unexpectedly advanced features to our specifications with ease. In the early days of development, Java, Scala, and Ruby were more experienced, so it was a bit of a struggle, but finally I’m starting to get the feeling that I can do most of the implementation in Go.
When I come up with an interesting implementation or a good library, I’d like to introduce it again.