25th September 2023 #cli #figma #waterminttoolbox Sometimes you want to export a batch of files created in Figma as a PDF, png or other format. For example, you may want to search for a memo you wrote on a sticky somewhere among several FigJams. This kind of search does not work because FigJam’s search does not look at the contents of the file, although it can search for file names and people.
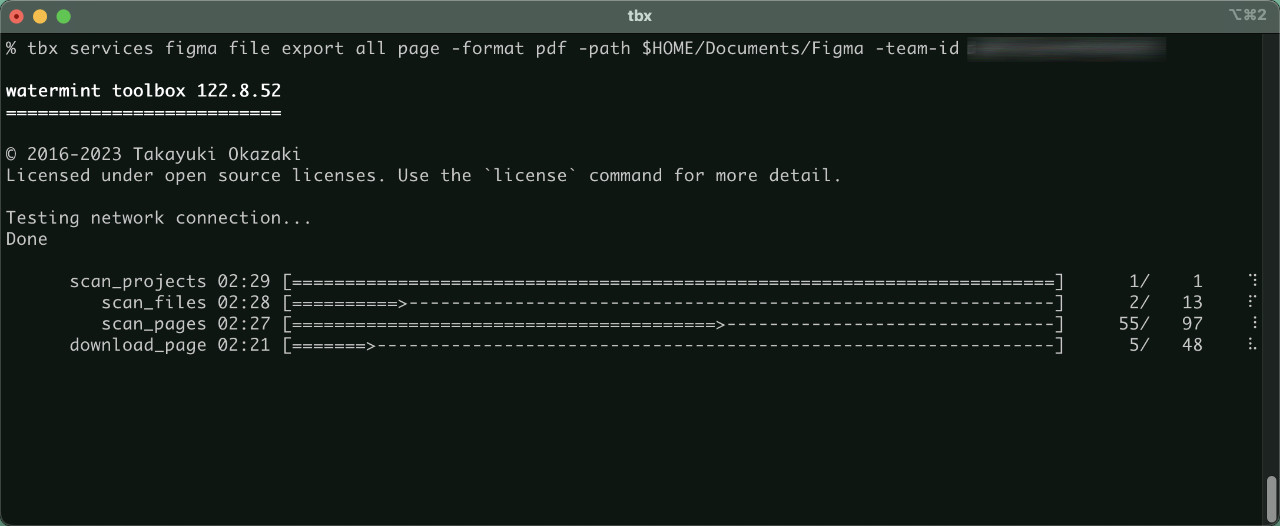
At least you can know which file you wrote it in, so if you export all your project files as PDFs, you can manage the rest. Using the OS’s full-text search of files or cloud storage searches such as Dropbox is a solution. Automation is essential to establish this kind of workflow, as Figma fortunately uses an API to handle these export processes, I have integrated the functionality into my own open source tool watermint toolbox.
This tool is a command-line tool, so it may seem difficult for those unfamiliar with it, but once you automate it, you can’t go back, so it’s not too much of a loss to learn it.
Commands for Figma
The watermint toolbox provides commands for several supported services, such as Dropbox and Github, to perform the process. Commands for Figma include.
Usage
Figma has the following structure from an API perspective.
Team -> Project -> File -> Page -> Frame -> Node
Each is managed by an ID number, and to export a file or page, you first need to know the starting team ID. The team ID can be found in the URL of the link to the team, which is the number following the team/ in the address when you select a team in Figma and copy the link.
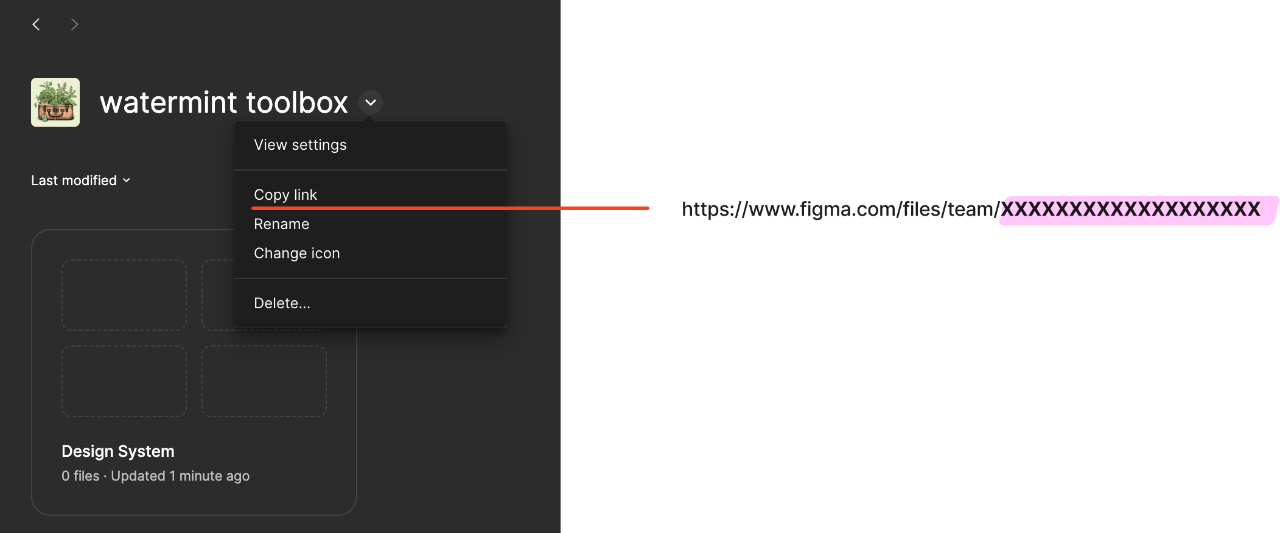
Download the latest version of the watermint toolbox. Extract the downloaded zip file and you will find an executable file called tbx or tbx.exe, which should be placed in an easily accessible location, such as a desktop folder.
Open PowerShell for Windows or Terminal.app for macOS. Once opened, cd Desktop to the desktop (or the folder with the tbx executable) and execute the command as follows.
./tbx services figma project list -team-id xxxxxxxxxxxxxxxxxxxxx
(replace xxxxxxxxxxxxxxxxxxxxxxxxxxxx with the team ID you have just obtained from the team address).
The first time you run the application, you will be asked to authorise it as follows, so press Enter to launch the browser.
If you are happy, authorise the application. Then, when “Success” is displayed on the screen, authentication is complete.
% watermint toolbox 122.8.52
==========================
© 2016-2023 Takayuki Okazaki
Licensed under open source licenses. Use the `license` command for more detail.
Testing network connection...
Done
Opening the authorization URL:
https://www.figma.com/oauth?client_id=XXXXXXXXXXXXXXX&redirect_uri=http%3A%2F%2Flocalhost%3A7800%2Fconnect%2Fauth&response_type=code&scope=file_read&state=XXXXXXXX
Please press ENTER to open the auth page on the browser.
When execution is completed, a list of projects and their IDs will be displayed as follows. If there are a large number of projects, some will be omitted, so please refer to the CSV or xlsx file in the path displayed at the end of the run.
% ./tbx services figma project list -team-id xxxxxxxxxxxxxxxxxxxxx
watermint toolbox 122.8.52
==========================
© 2016-2023 Takayuki Okazaki
Licensed under open source licenses. Use the `license` command for more detail.
Testing network connection...
Done
| id | name |
|----------|---------------|
| xxxxxxxx | Design System |
| xxxxxxxx | Workspace |
| xxxxxxxx | toolbox |
Similarly, if you want to get a list of the project’s files, run the following command.
% ./tbx services figma file list -project-id xxxxxxxx
watermint toolbox 122.8.52
==========================
© 2016-2023 Takayuki Okazaki
Licensed under open source licenses. Use the `license` command for more detail.
Testing network connection...
Done
| key | name | thumbnailUrl | lastModified |
|------------------------|--------------|--------------|--------------|
| xxxxxxxxxxxxxxxxxxxxxx | essentials | | |
| xxxxxxxxxxxxxxxxxxxxxx | web | | |
If you have the required file, get the key of this file and run the following command. This will export the file as a PDF in the folder where you run it. You can also choose to output png, svg or jpg with the -format option.
% tbx services figma file export page -key xxxxxxxxxxxxxxxxxxxxxx -path ./
watermint toolbox 122.8.52
==========================
© 2016-2023 Takayuki Okazaki
Licensed under open source licenses. Use the `license` command for more detail.
Testing network connection...
Done
1 page(s) found in the Figma file
page 00:02 [==========================================================================] 1/ 1 DONE
The command finished: 7.302s
This command is per file, but there are also commands to output nodes and to export all files under the team, so you can use them as needed.
24th September 2023 #cli #figma #waterminttoolbox Figmaで作成したファイルをPDFやpngなどの形式として一括してエクスポートしておきたいことがあります。 たとえば、複数あるFigJamの中でどこかのスティッキーに書いたメモを検索したいとします。 Figmaの検索はファイル名や人の検索はできますが、ファイルの中身までは見てくれないためこういった検索がうまくいきません。
せめてどのファイルに書いたのかわかればよいので、プロジェクトファイルをPDFとしてすべてエクスポートしておけば後はなんとでもなります。 OSのファイル全文検索やDropboxなどのクラウドストレージの検索を使えば解決です。 こういったワークフローを確立するには、自動化が欠かせません。Figmaでは幸いAPIを利用してこれらエクスポート処理ができるようなので、 自作オープンソース ツールである watermint toolboxに機能を組み込んでみました。
このツールはコマンドライン ツールですのでなじみのない方には難しく感じるかもしれませんが、一度自動化してしまうと戻れなくなりますので、習得しておいてもさほど損ではないかと思います。
Figma用のコマンド
watermint toolboxはDropboxやGithubなどいくつかの対応サービスに対して、コマンドを指定して処理を実行するようになっています。 Figma向けのコマンドは次のようなものがあります。
使い方
FigmaはAPI視点で見ると次のような構造になっています。
チーム -> プロジェクト -> ファイル -> ページ -> フレーム -> ノード
それぞれID番号で管理されており、ファイルやページをエクスポートするにはまず起点となるチームIDを知る必要があります。 チームIDは、チームへのリンクURLから知ることができます。Figmaのチームを選択して、リンクをコピーしたときの、アドレスの team/ に続く数字がチームIDです。
最新版のwatermint toolboxをダウンロードします。ダウンロードしたzipファイルを展開するとtbxまたはtbx.exeという実行ファイルがありますので、これをデスクトップフォルダなどわかりやすい場所に置いてください。 Windowsの場合はPowerShell、macOSの場合はTerminal.appを開きます。開いたら cd Desktop としてデスクトップ(またはtbxの実行ファイルを置いたフォルダ)に移動して次のようにコマンドを実行します。
./tbx services figma project list -team-id xxxxxxxxxxxxxxxxxxxxx
(xxxxxxxxxxxxxxxxxxxxxは先ほどチームのアドレスから取得したチームIDに読み替えてください)
初回実行時には次のように認証が求められますので、エンターを押してブラウザを起動します。アプリケーションのアクセス範囲など確認が表示されますのでよければ認可します。画面に「Success」と表示されれば認証完了です。
% watermint toolbox 122.8.52
==========================
© 2016-2023 Takayuki Okazaki
Licensed under open source licenses. Use the `license` command for more detail.
Testing network connection...
Done
Opening the authorization URL:
https://www.figma.com/oauth?client_id=XXXXXXXXXXXXXXX&redirect_uri=http%3A%2F%2Flocalhost%3A7800%2Fconnect%2Fauth&response_type=code&scope=file_read&state=XXXXXXXX
Please press ENTER to open the auth page on the browser.
実行完了すると次のようにプロジェクトの一覧とIDが表示されます。プロジェクト数が多い場合、一部省略されますので実行時の最後に表示されるパスのCSVやxlsxファイルを参照してください。
% ./tbx services figma project list -team-id xxxxxxxxxxxxxxxxxxxxx
watermint toolbox 122.8.52
==========================
© 2016-2023 Takayuki Okazaki
Licensed under open source licenses. Use the `license` command for more detail.
Testing network connection...
Done
| id | name |
|----------|---------------|
| xxxxxxxx | Design System |
| xxxxxxxx | Workspace |
| xxxxxxxx | toolbox |
同様にプロジェクトのファイル一覧を取得したい場合には、次のコマンドを実行します。
% ./tbx services figma file list -project-id xxxxxxxx
watermint toolbox 122.8.52
==========================
© 2016-2023 Takayuki Okazaki
Licensed under open source licenses. Use the `license` command for more detail.
Testing network connection...
Done
| key | name | thumbnailUrl | lastModified |
|------------------------|--------------|--------------|--------------|
| xxxxxxxxxxxxxxxxxxxxxx | essentials | | |
| xxxxxxxxxxxxxxxxxxxxxx | web | | |
必要なファイルがあれば、このファイルのkeyを取得して次のようなコマンドを実行します。 これで実行したフォルダにファイルがPDFとしてエクスポートされます。 -formatオプションで png, svg, jpgの出力も選択可能です。
% tbx services figma file export page -key xxxxxxxxxxxxxxxxxxxxxx -path ./
watermint toolbox 122.8.52
==========================
© 2016-2023 Takayuki Okazaki
Licensed under open source licenses. Use the `license` command for more detail.
Testing network connection...
Done
1 page(s) found in the Figma file
page 00:02 [==========================================================================] 1/ 1 DONE
The command finished: 7.302s
このコマンドはファイルごとですが、ノードを出力するコマンドやチーム配下のファイルをすべてエクスポートするコマンドも用意してありますので必要に応じてお使いください。
31st December 2022 #go #rust #waterminttbx #waterminttoolbox 趣味とある程度の実用性を備えたプログラムとして watermint toolboxと最近始めたtbxというプロジェクトがあります。watermint toolboxは既に何度か紹介していますが、Dropbox向けのコマンドラインツールとして開発を始め、今はそれ以外にも多様なコマンドを備えるプログラムとして成長しました。執筆時点で、最初のコミットからおおよそ6年(最初のコミットが2016年11月)、toolboxとして集約する前のいくつかのサブプロジェクトも含めると6年半ほどになります。

プログラムの仕様想定として、WindowsやmacOSなどの環境で追加ライブラリ等を必要としない、いわゆるシングルバイナリ配布できることを重視していたのでプログラミング環境としてはGoを選択しました。当時も他の言語選択肢はありましたが、Better Cとして名高いこと、開発環境の成熟度(≒IntelliJ Goプラグインの成熟度)、学習環境(Stackoverflowや書籍等の情報源)の充実度を考慮して決めたのだと思います。
この6年間、Goでプログラムを作ってみた成果として「Goらしくプログラムする」こともそれなりに成功したと思っています。フルタイムの仕事としてプログラムをしていたときは、言語仕様を読んだり著名なライブラリ・プログラムの設計解説や、コードを読んだりして自身の設計や開発に適用したものですが、趣味としてプログラミングを継続させようとすると違ったアプローチが必要になります。
趣味として成立させるにはある程度短期的に達成できる成功体験が不可欠と考えています(仕事として成立させるにも重要ですが場合により、必須ではない)。具体的にはプログラミング言語のチュートリアルとしてHello Worldの出力に始まり、ファイル入出力、簡単なモックアップやプロトタイプ作成、少し本格的な設計の取り込み、開発規模拡大に従う課題への対応と進んでいくかと思います。この一つ一つの段階があまり飛躍し過ぎてしまうと趣味としての継続が難しいと考えています。仕事であれば、ある程度段階が飛躍したとしても時間や費用をかけ習得したり、先達の助けを借りてこの飛躍を乗り切ることもできるでしょう。
継続は力なりと言いますが、一方で継続を実現するにはある程度の成功体験を繰り返せるための計画性も必要になってくると思いますし、実際watermint toolbox開発でもそう実感しました。この実感には裏づけとなる失敗・成功を含む別例があります。
結果的には同じようなプログラムを何度も作っているのですが、2013年から2015年にかけてScalaで開発していたプロジェクトがあります。このプログラムはもともとDDDやScala言語の理解を深めるために始めたものですが、ある程度の複雑性がある具体的なユースケースが欲しいと思い日常的に必要な課題解決(チャット操作の効率化やクラウドストレージへのファイルアップロードなど)を実装したものです。DDDやScalaの理解という意味ではある程度進んだのですが、設計がやや壮大過ぎたこともありDDD・Scalaの理解がある程度進んだという最初の(やや曖昧な)ゴールを達成したことで自然消滅的にプロジェクトが終了しました。
当初ゴール達成という意味では成功なのですが、失敗だと思っているのはせっかく2弱年もかけて作ったプログラムがあまり自身の資産になっていないというところが大きな理由です。その点、watermint toolboxではプログラムとしての綺麗さやGo言語の習得という以上に、実用性をより重視して短期的な問題解決を優先したこともあり短期的に成功体験が得られ、より継続的な開発が進められるようになりました。

今年2022年は、コロナ禍がある程度定常的なリスク・コストと認識され仕事上でも出張が再開された年でした。今年は海外へ行く機会があり、長時間フライト中は普段できない考えの整理ができるということでwatermint toolboxについても今後どうするか考えることにしました。
watermint toolboxは趣味と実用という意味ではなかなかの成功を収めたと思っています。これをさらに10年・20年とライフワーク的に開発し、資産として形成するにはどうすればよいか考えました。一つの議論はこのままGo言語で開発を進めるかということです。
Goは手軽さやエコシステムの充実といった意味で非常に優れていると思っています。一方でいくつかの理由によりある程度の大きさのプログラムを保守するのも難しそうだとも感じています。理由をある程度絞ると次の二つが挙げられます。
一つ目は型システムがJavaやScalaなどと比較しあまり充実しておらず、特にインタフェースの設計と実装ならびに保守がなかなか手間がかかることです。Go 1.18では待望のGenericsが導入されましたが、誤解を恐れず言えば適用範囲は限定的で関数の定義をマクロ的に複数型対応にコンパイル時に展開してくれる。という程度のもので、変数の宣言や構造体にGenericsのフィールドを定義できないなど型情報を資産として形成できるほどの機能はありません。このため、たとえばある型の配列から条件に合う値のみを抽出して別の配列を作成するという処理もGoでは毎回forループを書かなければなりません。そのforループにバグがあったりテストを書いたりしなければならないコストは趣味のプログラムには無視できない大きさです。
二つ目はエラー処理です。前述の型とも関連しますが現状のGo Genericsでは Javaでいうjava.util.Optional<T>・ScalaでいうOption[+A]といったnullに頼らないライブラリ群の構築ができません。Goでのエラー処理は戻り値リストの最後にerrorを返すというのが慣例です。この、errorもerrorインタフェースを実装したポインタということで、毎回型を調べてキャストしたり、別関数で判定したりと統一感もなく注意深くドキュメントを読んだとしてもエラー処理にまつわる不具合を生じやすいことが大きな問題だと感じています。
たとえばファイルが指定パスに存在するかどうかはGoでは次のように判定します。
_, err := os.Lstat("/path/to/file")
if os.IsExist(err) {
// 存在する場合の処理
}
このLstatが返すエラーは PathErrorという構造体のものですが、このエラーの詳細を知ろうとする場合は次のようにキャストして調べる必要があります。errorは実際にはどのような型のものかドキュメントやソースを見なければ分からず、Javaでいうところの、全てjava.lang.Exceptionとして例外を扱っているようなものです。議論の余地はあるでしょうけれど、Goで6年プログラムしてみて有益と感じたことはありませんでした。
_, err := os.Lstat("/path/to/file")
if os.IsNotExist(err) { // ファイルが存在しない場合の処理
switch e := err.(type) {
case *fs.PathError:
fmt.Printf("Op[%s] Path[%s] Error[%s]\n", e.Op, e.Path, e.Err)
}
}
Goのエコシステム、プログラミング環境の充実度はすばらしく、たとえばQRコードを作るプログラムを作りたいなと思ったとき、boombuler/barcodeのようなライブラリがすぐに見つかります。 短期的な成功体験を得るという趣味のプログラムを支えるにはぴったりです。
しかし、10年後に資産となるプログラムという意味では少し言語機能が不足していると感じるのと、ある程度プログラムが大きくなってきた時に駆られる「全部書き直したい」というモチベーションを考慮して並行して新しいプロジェクトを始めることにしました。
新しいプロジェクトを始めるにあたって、6年前と比べればプログラミングの環境も大きく変わったように見えます。GraalVMやKotlin Native、Scala Nativeなどの登場・成熟で実行ファイルのバイナリ配布の敷居が下がり、選択肢が増えました。TIOBEのプログラミング言語コミュニティ指標を見てみると、Pythonがこの5〜6年で急成長しトップになり、Javaは今月発表された結果ではついにトップ3から陥落し4位になるなど様変わりしたようです。
新しいプロジェクトの言語をどれにするかは2ヶ月ほど悩んだ結果、Rustを使うことにしました。選定理由はGoではない言語にしようと考えた理由である(1) 型周りが充実していることが最重要で、(2) エコシステムがある程度大きく必要なライブラリが探せること、(3) どうせなら本格的にプログラミングで使ったことのない言語といった理由からです。
趣味のプログラムとしてRustを始めるにあたっては、バランスの問題でwatermint toolboxを始めた頃と比べて違う計画を立てました。watermint toolboxは短期的な成功体験を継続することで成長させてきましたが、新しいプロジェクトで同じことをやると新しいプロジェクト側の方が当然楽しくなってしまい、旧プロジェクトを触らなくなってしまいます。
これを避けるために新プロジェクト側はある程度長期的なゴール設定をし2つのプロジェクトを並行して進めることにしました。watermint toolboxは引き続き短期的な問題解決のために、tbxは10年後を見据えた資産にしていくことに。tbxでは、具体的な実行可能プログラムよりはライブラリ群を最初に整備していくことでRustを習得しつつ、ある程度加速的に開発できる状態までライブラリ群が成熟した段階でwatermint toolboxの機能を逐次取り込み置き換えを目指すというものです。
Rustを習得するにあたっては、いくつか順番をおって実装していくことにしました。まずは文字列操作、続いてUUIDなど今後利用するであろうライブラリの実装、乱数など外部ライブラリをラッピングしたライブラリの構築といった順番です。細かくテストできる範囲から実装することで、所有権などRustならではのコンセプトを学びます。既存の優れたライブラリをラッピングすることは漢字の書き取りのような感じで、読むだけでは思いつかないテクニックや設計が学べます。
おそらくこのようなライブラリ群で文字列、数値、時間、KVSやデータベース、ログなどを実装またはラッパーを実装することで学びを深め、1〜2年後ごろから本格的な実装をしていくという予定です。果たしてこのような計画で進めるかはわかりませんが、継続を優先し楽しく来年もコードを書いていきたいと思います。

皆様もよいお年をお迎えください。
18th September 2022 #cli #monitoring #toolbox #waterminttoolbox 色々と検証作業をしていると様々な情報が欲しくなる。プログラムがうまくいかなかったのがCPUを使い切ったからなのか、ネットワーク帯域が足りなかったからなのか大まかには知りたい。
こういう時、まずOSごとに装備されているモニタリングツールが違うのでWindows、macOS、Linuxを混在環境で使っているとこの時点で毎回この差異に気をつかう。データを時系列で残すのも難しくはないが、ちゃんとやるとなかなか面倒だ。かといって、本格的なモニタリングツールの導入は監視サーバを立てたり監視サーバまでのネットワーク疎通はどうしようかと悩んでいると結局そこまで準備するぐらいなら今回は諦めようとなる。
CPU負荷やネットワーク状況、ストレージIOなど欲を言えばIOPSが欲しいとか、毎秒の分解能が欲しいとか、プロセスごとのCPU・メモリ利用が欲しいとか様々欲しくなるが、まずそういった細かな情報よりも最低限の情報がささっと手軽にとれるツールが欲しい。
なければ作れば良いということで、2016年よりコツコツ開発しているwatermint toolboxというプロジェクトのコマンドの一つとして実装した。
今回はまだモニタリングして情報収集するところまでで、分析をするツールまでは作っていない。取得するデータはJSON形式データで集まるのでまずはJSON加工ツールや簡単なスクリプトを書いて分析するつもりのため、分析はまた将来的な拡張のお楽しみに。
概要
今回はutil monitor clientというコマンドとして実装した。 watermint toolboxはマルチプラットホーム対応でWindows、macOS (x64/M1)、Linux (x64/arm64)に対応したそれぞれのバイナリを配布している。シングルバイナリ動作するようコンパイルしてあるので、ほとんどの場合追加ライブラリは必要なく動作する。(なお、Alpine Linuxの場合はTBX on Alpine Linuxを参照)
このモニタリングツールはデフォルトでは10秒間隔で各種統計を取り、1時間に一度ローカルディスクに蓄積してあるデータをDropboxへ同期する。同期完了後にローカルディスクのデータは削除される。データはすべてDropboxのフォルダに集約されるので、監視サーバを立てたり、監視サーバまでの通信経路に気を遣わなくてもインターネットにさえ出られれば良い。
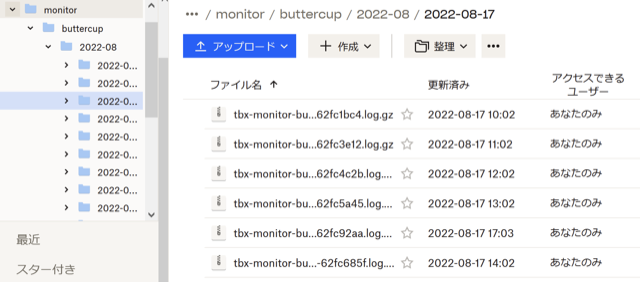
データは自動的に 対象名/yyyy-mm/yyyy-mm-dd/tbx-monitor-対象名-UNIXTIME.log.gz のようなフォルダ・ファイル名でgzip圧縮形式で保存される。また、watermint toolboxがクラッシュしてファイルがアップロードされていない場合は、再度同じように実行すれば次回実行時の同期処理時にすべてのファイルをアップロードする。なお、同期処理前はgzip圧縮が未実施のためローカルディスクの消費は1時間分で500KiB程度のサイズとなる。
ファイルサイズは概ね圧縮後で50KiB (10秒間隔・1時間分)、1日分でおおよそ1.2MB程度になる。これならば数週間といった単位で数台を監視してもさほど気にならないと思う。将来的には分析ツール部分を作る際にTSDBに格納しながらもう少しコンパクトなデータ形式で格納することになると思うが、今のフォルダ・ファイル形式でも分析までの受け渡しとしてはこの程度で良いだろうと思っている。
使い方
コマンド実行オプションなど詳細はutil monitor clientを参照いただきたいが大まかな流れは次の通り。
- 初回実行時にログをアップロードするDropboxアカウントへの認証を求められる
- 表示されたURLをブラウザに貼り付け認可
- その後表示されるコードをプログラムに貼り付ける
認可で取得した認証トークンは $HOME/.toolbox/secrets/secrets.db に格納される。2度目以降の実行ではここから認証トークンを取得するので再認証は不要である。
また、認証トークンを格納するファイルは -auth-database オプションでも指定可能である。たとえば次のように実行すると $HOME/Desktop/secrets.db に認証情報が保管される。
$ tbx util monitor client -auth-database $HOME/Desktop/secrets.db -name MONITOR_NAME -data-path $HOME/.toolbox/monitor -sync-path /monitor
これを応用すれば仮想マシンなどで認証操作をとばして監視を実施したい場合でも、認証データファイルと一緒にデプロイすれば良い。当然ながら、認証データファイルはパスワードと同様のものなのでアクセス権限などをしっかり設定することは前提となる。
長期間モニタリング
watermint toolboxはデバッグのために各種ログを自動的に出力するようになっている。これらのログは問題原因を探るには良いのだが、長期間モニタリングするにはストレージ容量を圧迫する懸念があるかもしれない。watermint toolboxは自動的にログローテートし一定サイズ以上にログファイルが肥大化しないように設計しているが、プログラムのクラッシュ等で回収しきれないログが残存する場合もある。
このような場合は次のように -skip-logging オプションを追加すると良い。このオプションにより、ほとんどのログがストレージへ書き込み処理なく実行されるのでログによるストレージ圧迫の懸念がなくなる。
$ tbx util monitor client -auth-database $HOME/Desktop/secrets.db -name MONITOR_NAME -data-path $HOME/.toolbox/monitor -sync-path /monitor -skip-logging
まだログの解析部分についてのプログラムがないので、負荷モニタリングという意味では道半分というところだ。今回のモニタリングプログラムについては、gopsutilプロジェクトの成果物を利用させていただいたので、ほぼ技術的な困難性はなかった。あえていうと、認証トークンが簡単にデプロイできるよう認証まわりのフレームワークを大きく書き換えたことが最も困難性が高かった。
またいつになるかはわからないが、解析編として解析プログラムが出来上がったときには紹介したいと思う。s
28th March 2022 #gadget ブレーカー付きタップを複数設置しようとすると、タップの出っ張りが干渉して複数設置できないという悲しい状態になりました。 タップを綺麗に配置したかったので今回は複数のブレーカー付きタップを準備して検証しました。 残念ながら今回準備したどのタップメーカーも寸法仕様がWebページ上にないようだったので、これから購入される方の参考になれば。

上図は左からオーム電機のHS-TMP2HH3-W、HS-TM1AHL3-W、ヤザワのY02FUBHKS210BK、朝日電器 ELPAのA-S400Bと並べた様子。 こうして並べてみるとわかりやすいのですが、プラグ部分から上の出っ張りが各社まあまあ違います。この中ではELPAが最も出っぱっていて、他のコンセントに干渉しやすい形をしています。
なおHS-TM1AHL3-Wはブレーカーはついていない発煙ガードタップ。発煙ガードとは、オーム電機の特許で内部温度が150度以上になると自動的に通電が遮断されるヒューズのような安全装置のよう。 動画での解説を見る限りはヒューズのように使い捨てになる模様。HS-TMP2HH3-Wはブレーカーに加え、この発煙ガードが付いているよう。
さて、ヤザワ・朝日電器のものはプラグ部分からタップ上部まで出っ張りがあり、ここが干渉します。 出っ張り部分の長さを調べてみると、ヤザワ・朝日電器は17mm以上あります(下図はヤザワのY02FUBHKS210BK)。

オーム電機のものはHS-TMP2HH3-WもHS-TM1AHL3-Wも9mm〜10mm程度。

壁側2口コンセントの間隔を測ると24mm程度。 つまり2つ設置したい場合、出っ張りは12mm以内である必要があります。 (3口コンセントの場合はさらに狭くなります)

このため消去法でオーム電機 HS-TMP2HH3-Wのみがブレーカー付きタップとして2つできる唯一のもののよう。

2つ刺してみても少し余裕があってとてもレイアウトしやすいタップだということがよくわかりました。