5th December 2020 #amazondrive #amazonphotos #dropbox #facebook #flickr #googlephotos #icloud 4年前の記事10万枚を超える写真データの整理とストレージ選びでは、NASなどのストレージに格納された18TBの重複を含む写真を、重複排除した上でAmazon Photos、Dropbox、flickr、Google Photosに移行したことを紹介しました。
今回は、次のような理由で複数クラウド上に保管しているデータを9月中旬からの約2ヶ月をかけてiCloudとDropboxの2つに集約しました。
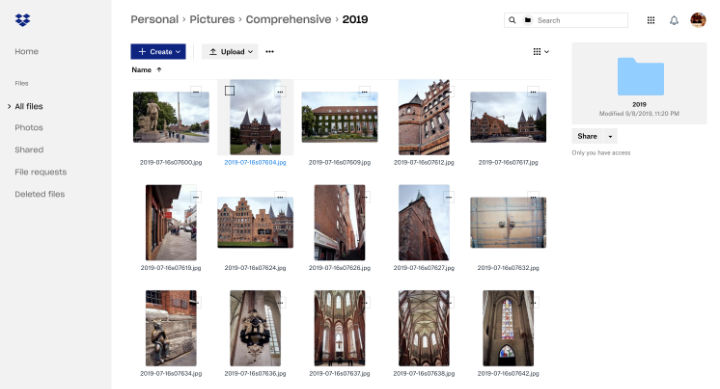
今回タイミング良く(?)、11月に2021年6月よりGoogle Photosのストレージ消費ポリシーが変わることが発表された時点では移行が完了していました。本記事がこの変更を受けて同様の移行を検討されている方の参考になれば幸いです。
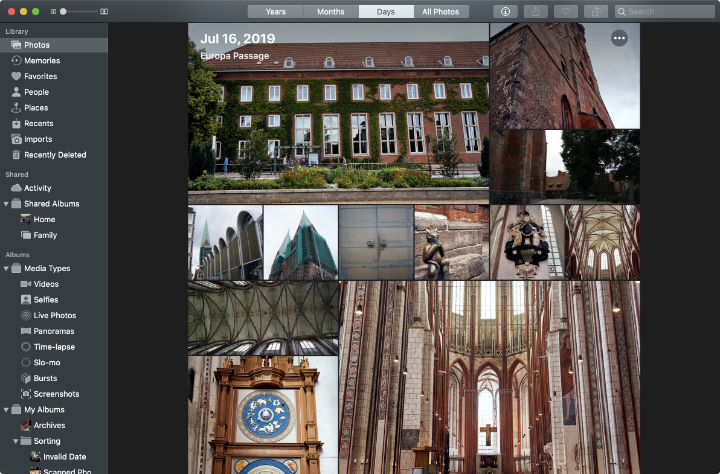
今回の移行には次のように、いくつかのモチベーションがありました。
- 検索性の問題 : 前掲の記事でいう★3つ以上の高評価写真についてはよく整理していたので問題ありませんでしたが、それ未満のあまり管理していない写真は複数クラウド上で管理すると、あまり検索性が高くありませんでした。
- 通信量の問題 : 4年前はあまり意識していませんでしたが、iPhone・iPadなどのモバイル端末で昔の写真を振り返るケースが増えました。Google Photosを利用していて一晩で20GB分ぐらいの通信クレジットを使い切ってしまったことがありました。
- 閲覧性の問題 : Google Photosは顔認識などの検索がなかなか便利ですが、iCloudの写真アプリでの閲覧がかなり進化したため見劣りするなと感じています。また、やはり通常のファイルシステム上で扱えるかどうかも重要です。特に特定の写真を加工したり、読み込んでドキュメントに貼り付けるという処理をするときにも便利です。このため、高評価としていなかった写真についてもDropbox上に管理することにしました。
- 内容の差異 : Google Photos、iCloud、DropboxについてはiPhone・iPadアプリで撮影した写真を自動バックアップしていました。ただ、アプリの動作や通信状況によってはうまくバックアップが取得できていなかったケースがあり若干の差分が発生していました。
整理後の状態
最終的には3つの種別にわけて、次のような構成としてまとめました。
| 種別 | 保管場所 | 備考 |
| RAWデータ | Dropbox | 撮影年ごとにCapture Oneカタログとして保管 |
| 出力データ (JPEG) | Dropbox, iCloud | 撮影年/撮影年-撮影月/撮影年-撮影月-撮影日 日付順に並べ替えやすいようフォルダ/ファイル名をつけ保管 |
| プレビューデータ (JPEG) | iCloud | iCloud Photosに取り込み |
RAWデータは★3以上のものだけを残しあとは削除して整理しています。Dropbox上に管理しているので、あとで必要になった場合でも復元できますから作業効率が高まるよう積極的に削除します。オリジナルデータはほしいときにすぐ再加工できるようCapture Oneのカタログとして管理しています。参照用形式はすべてJPEGデータとしてそろえました。 なお、残念ながらCapture One 20は執筆時点でHEIF・HEIC形式に対応しておらず、iPhoneやiPadで撮影したファイルは直接扱えません。ファイル整理整頓の後はワークフローとしても見直す部分がありそうです。
出力データはRAWデータと同じファイル名で出力して管理しています。ファイル名は撮影年-撮影月-撮影日s連番 (例: 2020-12-05s00013) のような形式で全アルバムの中で一意になるよう管理しています。これにより出力ファイル側で検索して、RAWデータを探すことができ作業効率が良くなりました。
プレビューデータは長辺が2704ピクセルとなるようリサイズしたデータです。プレビューデータとして利用する際はほとんどの場合、10〜11インチのiPadを利用します。13インチ程度のディスプレイを将来的に利用するとしても、2700ピクセル程度あれば250dpi以上を確保できます。さらに高い解像度にするよりはファイルサイズを絞ることで、プレビュー速度やダウンロード速度とのバランスをいくつか実験のうえ決定しました。2704ピクセルは中途半端な数値ですが動画の規格にFull HDと4Kの間にある2.7Kという解像度があり、ここからとっています。
クラウドに格納されたデータ
クラウド上に格納されたデータを確認するのはなかなか手間がかかります。Dropboxのようにファイルシステム上に見えるサービスの場合であれば簡単ですが、flickrやGoogle Photosのように写真のデータベースとなっている場合にはすべてダウンロードして手元で展開する必要があります。まずは1週間以上かけてすべてのデータをダウンロードしました(やり直し含めて3週間ほどかかりました)。
合計で3.7TBほどになりました。写真枚数は合計すると80万枚ほどですが、重複を排除すると15万枚ほどになりました。
| サービス | 写真枚数 | サイズ (GiB) |
| Amazon Photos | 135,841 | 2,046.39 |
| flickr | 363,440 | 1,053.31 |
| Dropbox (カメラアップロード) | 19,389 | 243.73 |
| Google Photos | 234,233 | 200.54 |
| iCloud | 18,965 | 97.80 |
| Dropbox (高評価写真管理用) | 14,428 | 66.98 |
| facebook | 7,742 | 2.04 |
まずはAmazon Photosです。2TB程度格納していたので、同容量の空きストレージを準備し、Amazon Photosアプリケーションでダウンロードしました。これに1週間ほど。
ほかのデータについては一度Dropboxに集約してから処理しました。
flickrについてはアカウント情報のYour Flickr Dataからエクスポートできます。2019年1月にflickrのストレージプラン変更時にDropboxへ保存しておきました。Dropboxからのダウンロードはスムーズで丸一日程度で終わりました。flickrからダウンロードしたファイルは画像ファイルとアルバムやコメントなどのメタデータがJSON形式で保管されます。今回、メタデータは処理しませんでしたので画像ファイルのみを抽出しました。
Google PhotosについてはGoogle Takeoutにてエクスポートできます。Dropboxにそのままエクスポートする機能がありますので、まずはDropboxにまとめておき、そこからダウンロードしました。Google Photosもflickrと同様に画像ファイルとメタデータのJSONファイルが出力されます。
facebookのデータはFacebook から写真や動画をDropboxにインポートする機能ができましたのでこれを使いました。メタデータなどは無く写真ファイルがアルバム名のフォルダとして整理されて出力されます。
重複の排除とリサイズ、日付の調整
Amazon PhotosやiCloudにはすべてのRAWデータなどが格納されていましたが、評価★3未満のファイルについてはプレビューのみ残し、あとは削除することにしました。
最初重複の排除にはGeminiというアプリを使っていましたが、十分重複排除しきれないことと、ファイル数が多すぎてアプリが頻繁に停止してしまう状態なってしまいました。また、いくつかカバーできない要件もあることから、今回は重複の排除とリサイズ処理は自作プログラムで実行することにしました。
自作プログラムといっても、ImageMagickやmacOSに標準インストールされているsipsコマンド、ExifTool、phashionといった既存のライブラリを組み合わせたものであまり特殊な処理はしていません。
重複排除の際は、ファイルが全く同一のバイナリであれば簡単ですが、同じ写真で異なる解像度、または同じ解像度だがEXIF情報が異なるなど複数のバリエーションがありました。このため、(1) EXIF撮影日時情報が含まれること、(2) 最も解像度が高い、(3) 評価情報があればその評価順という3つの条件で優先順位をつけて最優先する写真を選択し、ほかの写真ファイルは脱落するという処理を実施しました。
EXIF情報の処理
試行錯誤が必要だったケースを紹介します。次のファイルは、EXIFのDateTimeOriginalとModifyDateの両方が記録されているケースです。1998年に撮影されたファイルを、2002年に編集しそれがEXIF情報として記録されています。
% exiftool images/1998-03-10s29812r0.jpeg
File Name : 1998-03-10s29812r0.jpeg
... 略 ...
File Modification Date/Time : 2016:05:21 08:25:18+09:00
File Access Date/Time : 2020:10:11 19:21:39+09:00
File Inode Change Date/Time : 2020:10:10 21:50:56+09:00
... 略 ...
Modify Date : 2002:12:30 20:37:20
... 略 ...
Date/Time Original : 1998:03:10 11:29:08
これをmacOS標準コマンドsipsで情報を取得すると次のようにModify Dateが日付として表示されます。
% sips -g all images/1998-03-10s29812r0.jpeg
... 略 ...
pixelWidth: 480
pixelHeight: 640
typeIdentifier: public.jpeg
format: jpeg
formatOptions: default
dpiWidth: 72.000
dpiHeight: 72.000
samplesPerPixel: 3
bitsPerSample: 8
hasAlpha: no
space: RGB
creation: 2002:12:30 20:37:20
make: FUJIFILM
model: DS-30
software: QuickTime 6.0.2
copyright:
このように扱うライブラリやツールによって最終的に処理として利用するフィールドが異なるケースがあります。今回は、プレビューデータからはModify Dateデータを削除し、Date/Time Originalだけを利用しました。
同一画像の検出と重複排除
解像度が違ったり、編集時に明るさや色などを調整した写真など元は1枚の写真でも、多いものでは100ファイル程度のバリエーションとしてばらばらに保管されている写真もありました。これらをまとめて、重複排除するために今回はpHashというハッシュアルゴリズムを利用しました。pHashについてはより詳しく紹介されている記事が簡単に検索できますのでここでは詳しく紹介しませんが、画像の特徴抽出して画像間の”ハミング距離”を算出し、距離が0に近ければ同一または類似の画像であると推測できます。
今回はすべての画像に対するハミング距離の組み合わせまでは計算せず、ハミング距離が0のものだけを抽出して重複排除しました。これにより、80万ファイルあった写真が15万ファイル程度まで絞れました。あとはiCloudのPhotosのAIなどにがんばってもらおうと割り切り、あまり深入りしないことにしました。
なお、pHashなどの計算処理は最新のIntel Core i9-10910 CPUをほぼフルに使っていてもそれなりに重い処理で、80万ファイルに実行するには一晩かかる処理でした。これを数回試行錯誤していましたので、最終的に満足のゆく状態になるまでには1〜2週間はかかったかと思います。
ファイル形式の統一とリサイズ
ファイルはJPEGだけでなく、ARW、NEF、DNG、PNG、GIF、TIFF、HEICなど複数のファイル形式がありました。プレビューとして扱いやすいようすべてJPEG形式に統一しました。
リサイズ処理は最初に何度か失敗を繰り返しています。最初、RAWで保管してあった全てのデータをCapture Oneに取り込み、自動調整をかけてJPEGに出力する予定でした。しかしながら、Capture Oneはライブラリに取り込んだファイル数が1万ファイルを超えたあたりから指数関数的に重くなり、10万ファイルを超える頃には実質使い物にならない状態になっていました。CPU負荷などを見ても何もしていないように見えたので、なんらかデッドロックしているものと考えられます。
また、10万ファイルを処理キューに入れた後失敗したので再試行しようとすると処理キューが開けなくなりCapture Oneが実質使えなくなる状態にまで陥りました。バッチジョブのデータは1件ずつ bplist形式で$HOME/Library/Application Support/Capture One/Batch Queue 13.0 フォルダ以下に保存されるようで、これらを削除するとなんとかジョブデータを初期化できました。
こうした結果を受けて、リサイズ処理については調整をかけずにすべてsipsコマンドでリサイズすることにしました。もう少し時間があればImageMagickとsipsでどちらが良いかなど比較したかったのですが、今回は妥協しました。
まとめ
2ヶ月程度の努力も実って無事、複数あったクラウド上のデータを2カ所にまとめることができました。3.7TBあったデータは1.04TBまで削減できました。 データ容量が減ったこともありますが、プレビューはiPhone・iPadから見違えるほど見やすくなりましたし、編集用ファイルも探しやすくなりました。十分投資対効果があったと感じています。また、この課程でいろいろ過去の写真を振り返るのも楽しい時間でした(このためなかなか整理が進まない)。
残念ながら重複排除などで利用したプログラムはあまり汎用性が高くないので、現時点では公開には耐えられないのですが、また別の機会に整理整頓が必要となった際には調整して公開したいと思っています。
21st November 2020 #amazonaffiliate #googleanalytics #privacy I used to use Google Analytics and Amazon Affiliate links on this blog, but I have removed them. I will no longer track visitors to my site. I have also removed the past Google Analytics logs.
This site currently use cookies only for delivery control, of delivery server Cloudflare’s cookie.
This time it’s not because there was any particular problem to deal with Google Analytics or Amazon Affiliate. But because I didn’t usually use of analytics or affiliates. Additionally, privacy protection would be essential in the near future.
More positively, the site’s display speed improved from a few seconds to about a second when I moved from WordPress to Tumblr and then from Tumblr to Github Pages. This time, I changed the delivery infrastructure from Github Pages to Cloudflare Workers. As a result, the display time became about 0.3 seconds, with the removal of Google Analytics. Finally, the site received a score of 100 in the evaluation by PageSpeed.
20th November 2020 #amazonaffiliate #googleanalytics #privacy 本ブログではGoogle AnalyticsとAmazon Affiliateのリンクをいくつか利用していましたが、それらを削除しました。これにより、本サイトにお越しいただいた方を追跡することはなくなりました。また、過去のGoogle Analyticsログについても削除いたしました。
クッキーについては現在は、配信サーバであるCloudflareのクッキーのみでこちらは主に配信制御用のものです。
今回は特に何か問題があったための対処ではなく、もともと分析やアフィリエイトも活用していなかったことと、プライバシー保護は今後基本的なものとなるだろうとの考えからです。
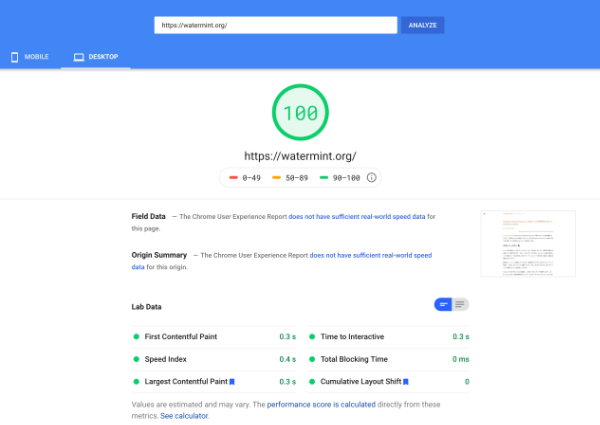
もっと良い作用としてはサイトの表示スピードが速くなりました。WordPressからTumblrへ移行し、TumblrからGithub Pagesへ移行したことで数秒かかっていた表示が1秒台ぐらいに改善していました。今回配信インフラをGithub PagesからCloudflare Workersに変更したことが大きいですが、最後の一押しとしてGoogle Analyticsの削除でさらに高速化され表示時間は0.3秒程度になり、PageSpeedによる評価も無事100点をいただけました。
4th November 2020 #cli #dropbox #dropboxbusiness #toolbox #waterminttoolbox watermint toolboxではDropboxまたはDropbox Business用のコマンドを各種揃えています。今回はDropboxの個人アカウントまたはDropbox Businessチーム全体に対する共有リンクを操作するコマンドを紹介します。
共有リンクの一覧
チーム内の共有リンクをすべてレポートとして出力することで、監査や管理上の資料として利用できます。なお、このコマンドではチームメンバー全員の共有リンクを取得して一覧を作成しますので、チームメンバー数が多い場合には相応の時間がかかります。
詳細はマニュアルに記載していますが、最新版のプログラムをダウンロードして解凍し、次のようなコマンドを実行します。なお、例ではプログラムをデスクトップに解凍したことを想定しています。
WindowsではまずPowerShellを起動し、次のようなコマンドを実行します。(なお、PowerShellへの依存関係はなくコマンドプロンプトやバッチファイルからの起動でも動作します)
まずデスクトップフォルダに移動します。
続いてプログラムを実行します。
.\tbx.exe team sharedlink list
これでしばらく待つとレポートが作成されます。レポートファイルはCSV、xlsx、JSON形式の3種類出力され、画面上にレポートが作成されたパスが表示されます。レポートの書式についてはマニュアルを参照してください。
全体のチーム内の共有リンク有効期限を上書きする
このコマンドでは共有設定で、リンクを知っている人全員となっているチーム内の共有リンクに対して有効期限を上書きすることで実質的には公開リンクを削除できます。有効期限の指定方法は現時点からの日数、または指定した日時です。
たとえば有効期限を30日後に設定したい場合には次のように実行します。
.\tbx.exe team sharedlink update expiry -days 30
これで全ての公開共有リンクの有効期限を30日に上書きします。なお、有効期限が30日以内であるばあいには上書きしませんので、定期的にこのコマンドを実行してチーム全体の有効期限を管理することも可能です。
また、指定日時での有効期限指定も可能です。たとえば、年度末を有効期限としたい場合には次のように実行します。
.\tbx.exe team sharedlink update expiry -at 2021-04-01
このように -at オプションに続けて日時を指定するとその日時で上書きします。 詳細はマニュアルをご参照ください。
28th July 2020 #cli #gmail #gmailapi #google #googleapi #toolbox #waterminttoolbox New Gmail-related commands have been added to the watermint toolbox. This allows you to get a list of emails from the command line, add/remove/rename labels, and add/remove filters.
% tbx services google mail label list
watermint toolbox 72.4.544
==========================
© 2016-2020 Takayuki Okazaki
Licensed under open source licenses. Use the `license` command for more detail.
Testing network connection...
Done
Opening the authorization URL:
https://accounts.google.com/o/oauth2/auth?client_id=xxxxxxxxxxx-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.apps.googleusercontent.com&redirect_uri=http%3A%2F%2Flocalhost%3A7800%2Fconnect%2Fauth&response_type=code&scope=https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fgmail.labels&state=xxxxxxxx
Please press ENTER to open the auth page on the browser.
| name | type |
|------------------------------|--------|
| CHAT | system |
| SENT | system |
| INBOX | system |
| IMPORTANT | system |
| TRASH | system |
| DRAFT | system |
| SPAM | system |
| CATEGORY_FORUMS | system |
| CATEGORY_UPDATES | system |
| CATEGORY_PERSONAL | system |
| CATEGORY_PROMOTIONS | system |
| CATEGORY_SOCIAL | system |
| STARRED | system |
| UNREAD | system |
| services/google.com | user |
| services/accounts.google.com | user |
| services/youtube.com | user |
The report generated: /xxxxx/xxxxxxxx/.toolbox/jobs/20200727-074430.001/report/labels.csv
The report generated: /xxxxx/xxxxxxxx/.toolbox/jobs/20200727-074430.001/report/labels.json
The report generated: /xxxxx/xxxxxxxx/.toolbox/jobs/20200727-074430.001/report/labels.xlsx
If you want to use it, please use Release 72 or later.
I label and manage each source to some extent as I process a variety of emails. This is also a bit of a hassle when the number of source types increases, and I counted the number of labels in the command I created this time, and there are already 343 labels.
% tbx services google mail label list -output json | jq 'select(.type == "user") | .id ' | wc -l
343
I checked the number of filters created in the same way and found 474.
% tbx services google mail filter list -output json | wc -l
474
I have been making labels and filters by hand for several years now, but it’s getting tedious, so I made it possible to create labels and filters in batches based on certain conditions. So far, it’s not fully automated, but semi-automated once the CSV data file is created.
Create the source data for the label/filter you want to create.
There are two types of Gmail labels. (1) system labels that are automatically assigned by Gmail, such as INBOX and SPAM, and (2) user-defined user labels. In this time, I’m going to get the list of emails in INBOX and get the data with no user labels attached. In this case, I will add label conditions based on the destination address and source address of the email.
First of all, get the email data, get the source address, and make rules for each domain. I’ve omitted quite a bit, but I get the mail data in JSON format, process it with the jq command and output it as CSV. The first column is the query, the second column is the label to be added, and the third column is the label to be removed. The third column is not specified. If you want to archive automatically, you can do so by deleting INBOX.
% tbx services google mail message processed list -output json | jq -r 'select(.label_type_user | length ==0) | .from.address | ["from:"+., "services/"+capture("@(?<d>\\b([a-z0-9]+(-[a-z0-9]+)*\\.)+[a-z]{2,}\\b)").d] | @csv' | sort -u
"from:families-noreply@google.com","services/google.com"
"from:googlecommunityteam-noreply@google.com","services/google.com"
"from:no-reply@accounts.google.com","services/accounts.google.com"
"from:no-reply@google.com","services/google.com"
"from:noreply-purchases@youtube.com","services/youtube.com"
Create a batch filter based on this data. It also automatically creates any missing labels and applies them to the messages in the INBOX.
% tbx services google mail filter batch add -add-label-if-not-exist -apply-to-inbox-messages -peer waterlandpier -file ~/filters.csv
watermint toolbox `dev`
=======================
© 2016-2020 Takayuki Okazaki
Licensed under open source licenses. Use the `license` command for more detail.
Creating a filter: from:families-noreply@google.com
from:families-noreply@google.com: Updating message 1
from:families-noreply@google.com: Updating message 2
Creating a filter: from:googlecommunityteam-noreply@google.com
from:googlecommunityteam-noreply@google.com: Updating message 1
Creating a filter: from:no-reply@accounts.google.com
from:no-reply@accounts.google.com: Updating message 1
from:no-reply@accounts.google.com: Updating message 2
from:no-reply@accounts.google.com: Updating message 3
from:no-reply@accounts.google.com: Updating message 4
from:no-reply@accounts.google.com: Updating message 5
from:no-reply@accounts.google.com: Updating message 6
from:no-reply@accounts.google.com: Updating message 7
Creating a filter: from:no-reply@google.com
Creating a filter: from:noreply-purchases@youtube.com
from:noreply-purchases@youtube.com: Updating message 1
| status | reason | input.query | input.add_labels | input.delete_labels | result.id | result.criteria_from | result.criteria_to | result.criteria_subject | result.criteria_query | result.criteria_negated_query |
|--------|--------|---------------------------------------------|------------------------------|---------------------|----------------------------------------|----------------------|--------------------|-------------------------|---------------------------------------------|-------------------------------|
| 成功 | | from:families-noreply@google.com | services/google.com | | xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx | | | | from:families-noreply@google.com | |
| 成功 | | from:googlecommunityteam-noreply@google.com | services/google.com | | xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx | | | | from:googlecommunityteam-noreply@google.com | |
| 成功 | | from:no-reply@accounts.google.com | services/accounts.google.com | | xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx | | | | from:no-reply@accounts.google.com | |
| 成功 | | from:no-reply@google.com | services/google.com | | xxxxxxxxxxxxxxxx-xxxxxxxxxxxxxxxxxxxxx | | | | from:no-reply@google.com | |
| 成功 | | from:noreply-purchases@youtube.com | services/youtube.com | | xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx | | | | from:noreply-purchases@youtube.com | |
The report generated: /xxxxx/xxxxxxxx/.toolbox/jobs/20200726-223228.001/report/filters.csv
The report generated: /xxxxx/xxxxxxxx/.toolbox/jobs/20200726-223228.001/report/filters.json
The report generated: /xxxxx/xxxxxxxx/.toolbox/jobs/20200726-223228.001/report/filters.xlsx
The report generated: /xxxxx/xxxxxxxx/.toolbox/jobs/20200726-223228.001/report/messages.csv
The report generated: /xxxxx/xxxxxxxx/.toolbox/jobs/20200726-223228.001/report/messages.json
The report generated: /xxxxx/xxxxxxxx/.toolbox/jobs/20200726-223228.001/report/messages.xlsx
I don’t usually have time to create filters in batches, so I’m hoping this will make my email processing a little more efficient.